企业实践开源的动机
随着开源软件全面占据软件供应链的各个阶段,商业公司开发基础软件或业务逻辑的时候,已经避不开对软件的使用了。经过一段时间对开源软件的使用,以及开源吞噬软件的趋势影响,研发能力突出的公司或团队,也会加入到开发开源软件的行列中来。
商业模型当中开源软件位置的不同,体现出企业实践开源动机的不同,并且会很大程度影响企业实践开源的行为。本文将讨论不同商业模型下,企业实践开源的动机和行为的差异。
商业模型是销售开源软件
第一类商业模型是直接销售开源软件。这种类型的企业以 MongoDB Inc. 和 Elastic 为代表,是在 2010 年以后逐渐兴起的企业类型。
不过,说它们是“销售开源软件”也不准确。虽然在早期它们的商业产品是直接提供当时还是开源软件的 MongoDB 和 ElasticSearch 本身,但是随后由于源代码免费可得,包括 AWS 在内的云厂商直接利用免费的源代码在平台上提供同类的服务,这样的新形势使得这两家公司前后把软件协议改成 Server Side Public License (SSPLv1) 和 Elastic License (ELv2) 来对抗商业竞争。
其中 ELv2 是明确的专有软件协议,禁止其他人提供同类的服务,也不允许破解付费密钥锁定的高级功能。SSPLv1 是对 GPL 系列许可的发展,但是要求与 MongoDB 一同构成服务的所有软件都需要按照 SSPLv1 协议发布,即包括开放源代码,这一点超出了 OSI 推出的开源定义第九条“协议不应该限制其他软件”的原则。实际执行过程中值得注意的是,MongoDB Inc. 采用 SSPLv1 的动机是对抗商业竞争,它同时鼓励用户购买企业提供的以专有软件协议发布的 MongoDB 以避免 SSPLv1 的要求。这种行为的动机与自由软件基金会制造的软件纯粹是为了让所有人能够自由地使用高质量的软件的初衷非常不同。因此,我并不将这样重新许可后的软件认为是开源软件,而是源码公开的专有软件。关于不同开源协议的讨论,我在《选择开源许可证》一文里有详细地展开。
无独有偶,曾经试图通过销售开源软件的公司,最终都走上了重新许可成源码公开的专有软件的路。
- Why are we changing the license for MongoDB?
- Upcoming licensing changes to Elasticsearch and Kibana
- Why We’re Relicensing CockroachDB
- A New License to Future Proof the Commoditization of Data Integration
另一方面,越来越多的技术创业公司难以抵挡“开放源代码”的潮流和用户与开发者心理预期的转变,又清晰地理解了自己的商业模式就是销售将要开放源代码的这个软件本身,因此它们一开始就选择了源码公开的专有软件协议来禁止其他厂商直接利用公开的源代码销售同类服务开展竞争。
- Business Source License 1.1
- MariaDB Projects using BSL 1.1
- Materialize is licensed under the Business Source License agreement
这种商业模式,本质上是 MongoDB Inc. 前任 CEO 所宣称的“免费增值”策略,即在不产生商业竞争的情况下,或者说对于用户,可以免费地使用该软件。等到用户深度参与之后,产生运维支持的需求,或者定制开发尤其是商业软件集成的需求,再转向唯一的供应商 MongoDB Inc. 付费获得支持。
我认为这种模式是说得通的,是一个好的市场营销手段。但是它与自由软件运动和开源运动的理念都是相违背的。
自由软件运动的理念是所有软件都应该能够被所有人自由地用于所有用途,显然用于提供托管服务就是其中一种用途,而上述软件协议不允许任何形式地提供同类托管服务。另一方面,自由软件运动的起源之一是 Richard Stallman 在打印机软件出现故障时无法取得源代码修复并重新编译和使用的痛苦。ElasticSearch 以付费密钥锁定的功能,是不是用户也需要的功能呢?如果我开发了同样的功能并且发布了,这里是否会产生破解的嫌疑呢?
开源定义(OSD)下的开源运动也包括了不限制用途和不限制其他软件的要求。进一步的,以 Apache 软件基金会为代表的开源世界,努力生产开源软件的基础是为了让所有潜在的参与者和用户平等地使用开源软件和参与开发。上述源码公开的专有软件,几乎只有相应商业公司的成员才能开发核心代码,并且解决的需求也是其客户提交的需求,随后进行商业交付。如前所述,如果有一个开发者完成了商业公司提供的付费功能并且期望合并到上游发布,上游会接受吗?
不过,抛开以专有协议许可的核心部分不谈,这些企业共同选择了在生态连接所需要的接口和模块方面,采用宽容的开源协议例如 Apache 2.0 或者 MIT 来许可。尤其是 Airbyte 提出的核心以 ELv2 许可的软件及其相应协议的模型,对于 CLI 和 Connector 等部分,都是开源软件。
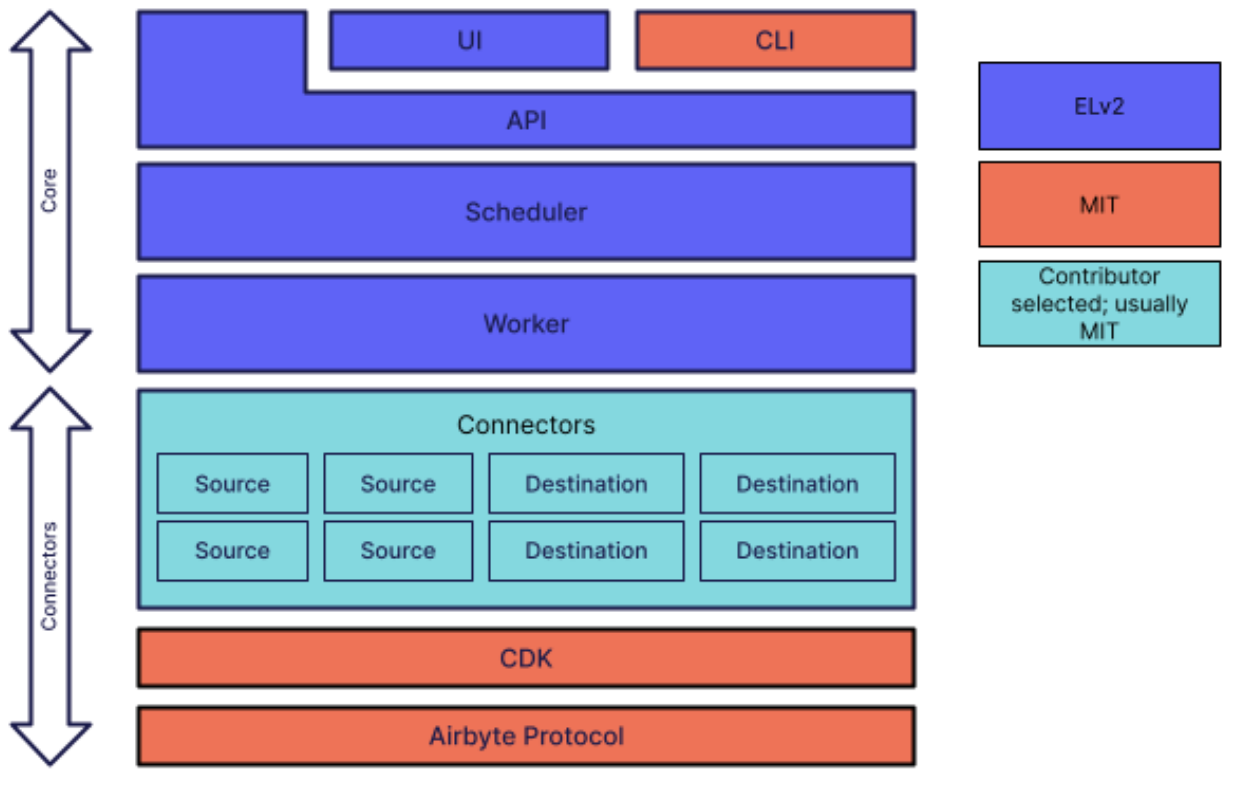
如果把源码公开的专有协议部分视作商业软件而非传统意义上的开源软件,那么这种形式与接下来要讨论的依托于开源软件的商业模型就有很大的相似性了。只不过,当下的市场没能很好地区分开开源软件和源码可得的专有软件。如果一个企业的商业模型就是销售“开源”软件本身的功能,例如前面提到的 MongoDB Inc. 和 Elastic 还有 CockroachLabs 这样的,那么他们的核心功能转向专有软件只不过是时间问题,或者说只要面临商业竞争,就是经不起挑战的。
对于这样的企业来说,它的核心软件只能依靠自己开发,是不可能大范围地借助开源协同的力量完善和覆盖尽可能多的场景的。而且由于商业上的排他性,其他得到资本支持的研发团队也很难直接参与到开发中来。这样的软件与过去的专有软件,都会在开源吞噬软件的浪潮下最终被取代。关于开源吞噬软件在工程上的论证,《大教堂与集市》一书当中的 2.12 节《管理与马奇诺防线》有详细地论证。
这类商业模型的企业制造的软件生态当中可能出现的协同,也局限于用户在没有其他开源软件选择的时候,根据自己的需要和上游以开源软件开发的组件的情况,相应的做一些补充。例如 Airbyte 支持其他数据源的导入,例如 GitHub 其实是个专有软件,但是在 toolkit 和 actions runner 以及 gh cli 等方面公开了相应的开源组件,这些组件也能得到开源社群的助力。
商业模型依托于开源软件
第二类商业模型是依托于开源软件构建商业产品。其实,在开源软件占据软件供应链各个环节的背景下,任何商业模型的依赖路径上存在计算机软件的,基本都会部分依赖于开源软件。当然,我们这里主要讨论的情形,是依赖深度较短的订阅咨询和解决方案的模型。这两者不是互斥的,往往一个企业会同时发展这两方面的商业产品和技术支持。
侧重订阅咨询的商业公司里,有名的包括红帽、收购红帽的 IBM 和收购了 Pivotal 的 VMware Tanzu 实验室。
这三家公司都是 Kubernetes 的重要参与者,提供类似于 Kubernetes 发行版的云平台 PaaS 订阅服务。红帽还以提供 Linux 发行版和技术支持闻名,VMware 则有 Spring 这个 Java 生态的杀手级开发框架背书。在 IBM 的开源软件技术支持列表里,涵盖了从应用开发栈、数据平台、云平台到 DevSecOps 等领域的一系列知名开源软件。
开源软件的源代码是公开且免费可得的,任何用户都能够自由编译、演绎和使用在任何场景下。但是,经过几十年软件行业的发展,以及社会生活数字化的浪潮,现在广泛被使用的开源软件已经复杂到没有经过专门的训练和经验积累,很难应对形形色色的业务需求。21 世纪最难得的真的是人才,上面提到的这些企业通过建立起开源社群当中属于自己的品牌,以及提供良好的工作环境吸引到高水平的软件开发人员,从而能够提供这些广泛存在于其他商业公司软件供应链上的核心开源软件的支持和订阅服务。
例如,红帽工程师耗费两年的时间打造了 Vert.x 反应式应用开发框架,并捐赠到 Eclipse 软件基金会共同创造出一个新的应用开发生态。厚积薄发,经过两年的设计开发和红帽客户资源增益的打磨,一个全新的开源软件和基于这个开源软件提供技术支持和订阅服务的商业模型正式成功上线。又例如,Pivotal 早在 2003 年就开始基于 PostgreSQL 开发 Greenplum 大规模并行处理系统,这个系统在经受 Impala 和 ClickHouse 等等后起之秀在十年之后的挑战之前一直代表相关领域的先进生产力。IBM 和 VMware 则是以收购见长,将这些已经成功走出订阅咨询路线的商业公司并入自己的企业服务版图,从而提供像上面 IBM 的开源技术支持那样全方位的服务。
阿里云、腾讯云和 AWS 等云厂商在其公有云平台上提供的开源软件托管服务,则是介于订阅和解决方案之间的商业模型。它们既有利用自己公有云平台和机器资源的优势,提供分毫未改的与开源软件相同的 API 的托管服务,例如 RDS 和 Redis 服务,也有发挥基础软件团队研发能力进行二次开发,产品能力升级或场景化定制的商业软件,例如 Ververica Platform 和 Tair 等等。
当然,售卖开源软件托管服务不是大型云厂商一家的专利。Upstash 和 Datastax 都捕捉到了关系型数据库以外,数据平台对 NoSQL 数据库在 KV 类型和消息系统类型的需求,分别基于 Redis + Apache Kafka 和 Apache Cassandra + Apache Pulsar 搭建了自己的托管服务。由于依赖的软件属于 Apache 软件基金会或其他第三方组织,即使这些企业接近于直接销售开源软件,但是也无法重新以专有协议许可,因此这些企业被迫会转向上面提到的订阅模型,或者这两家企业选择提供上述开源软件全球可用和高效治理的服务,以此来产生自己的附加值。
这种附加值可以认为是一个企业级的解决方案,选择了 Upstash 的 Redis 服务,就可以获得在欧洲、北美、南美和东南亚都符合当地合规要求的开箱即用的 Redis 接口。另一方面,可以认为是企业基于自己对企业软件生态的理解,提供的一套方法论。例如上一段提到这两家公司是组合了 KV + Messaging 的接口提供服务,认为这两者合作就能解决业务在边缘场景下的数据存储和上报消费的需求。
基于 Trino 分布式 SQL 查询引擎的公司 Starbrust Data, Inc. 全力推广 Data Mesh 的概念,基于 Apache ShardingSphere 的公司 SphereEx 则全力推广 Database Plus 和 Database Mesh 的概念。这都是商业公司以开源软件为核心,打造出的一套有商业差异化的企业软件生态最佳实践或者叫方法论。只要你信了这套方法论,以同样的架构,同样的开源软件为核心搭建企业的软件生态,那么进一步产生付费,支持这一生态的顺利和高效运转,就是顺理成章的了。
彻底以产品化的解决方案来封装开源软件提供商业价值的模式,典型的企业包括 Databricks 和 Tetrate 以及 Firebolt 等等。
说起 Databricks 这家公司,很容易想到的是他们的早期核心团队制造的 Apache Spark 开源软件。不过,Spark 早在核心团队还在大学实验室的时候就捐赠给了 Apache 软件基金会,因此同样改变软件协议来排他的销售软件是行不通的。Databricks 首先提供了具有明显性能优势的 Databricks Runtimes 产品,为对性能有极致追求的客户提供一个商业选择。然而,这样的用户毕竟是少的。于是 Databricks 开始了场景化的尝试,包括面向机器学习场景的 MLlib 和一系列的商业产品,包括面向一站式数据处理的 Delta Live Table 等组件,以及类似于上面提到的 Data Mesh 这样方法论的 LakeHouse 方法论与它的 DeltaLake 核心软件。
今天打开 Databricks 的官网,可以看到它早已在 Apache Spark 的基础上,长出了丰富的面向不同领域场景,面向不同用户案例和面向不同客户画像提供的一系列丰富的解决方案。构成这些解决方案的基础是 Apache Spark 丰富的生态,以及与开源的 DeltaLake 一脉相承的数据湖系统。在 Apache Spark 的名义下,在捐赠给 Linux Foundation 的 DeltaLake 的名义下,在 Databricks 官方 GitHub 组织的名义下,有着上百个连接数据平台开源共同体的开源软件。Databricks 在此之上又开发了面向不同场景不同解决方案需求的专有软件和商用代码,从而支撑起了自己的商业模型。
同样的,Tetrate 旨在提供云原生应用的网络治理方案。Tetrate 重度参与了 Istio 和 Envoy 以及 Apache SkyWalking 等开源项目的开发,雇员当中不乏相应社群的维护者乃至创始人。然而这家公司从未以相关开源社群所谓“背后的商业公司”自居,而是清晰地认识到自己的商业模式是依托于这些开源软件,提供自己定位在云原生应用的网络治理方案上所需的专有软件和企业级解决方案。Tetrate 有自己的 Istio 发行版,以在上游激进的发布模型之外为商业用户提供稳定、经过测试、高度兼容且 Tetrate 提供技术支持的 Istio 版本。此外,Tetrate 提供了 Tetrate Service Bridge 一揽子解决方案,在 Service Mesh 的方法论体系下支持客户将应用部署起来并完整监控和高效治理。
上面两个例子当中,Databricks 的工程师还有相当部分投入到 Apache Spark 和 DeltaLake 以及其他公司发布的开源软件的开发迭代,Tetrate 更是鼓励乃至促使重度参与提到的三个开源社群当中。Firebolt 的例子会有所不同,它很大程度上是作为 ClickHouse 的下游存在,极少参与上游开发。
Firebolt 仅将 ClickHouse 作为自己的计算执行引擎,在这一选型之外,完全专有化的实现了前台管控、集群管理和元数据管理、查询优化、数据索引和面向云存储的访问层。这样的商业模型也是依托于开源软件的,但是其依赖深度已经处于临界值。例如某些完全闭源的 Java 开发的专有软件,其中的网络模块也有可能使用开源软件 Netty 来实现,但是这种情形下,恐怕就不是我们这里所想讨论的企业实践开源的商业模式了。
Firebolt 这样的选型也算是自然的。如果你回顾 Databricks 的发展历程,它实际上可以被认为是选择了 Apache Spark 作为自己的计算执行引擎,逐渐发展出场景化的解决方案和 LakeHouse 一站式数据处理平台。不过,Databricks 的方向是逐渐走向开源。利用自己的先发优势,赚到行业内唯一提供商的收益以后,逐渐将自己的能力开源出来,以形成强凝聚力和活力的生态。这在下一节“开源标准以保护现有软件”会展开讨论。
反过来看 Firebolt 的做法,ClickHouse 在 fork 以后已经经历过闭源魔改,我相信时至今日它还是不是 ClickHouse 已经不好说了。Firebolt 也没有任何参与开源社群的征兆。因此我认为它会成为一个传统的商业软件公司,并在数据处理领域的开源浪潮下被吞噬。或许另一个世界当中的 Firebolt 走的是积极与上游协同的路线,共同发展 ClickHouse 的计算模块,并且在逐渐扩大自己商业版图的过程中把访问云存储的技术开源,查询优化和集群管理也开源,成为另一个行业标准的制定者。
回顾上一节当中我提到如果把源码公开的专有软件这一部分就明确认知成专有软件,上一节当中提到的商业公司也有形如 Databricks 和 Firebolt 这样不同的倾向性。虽然我相信开源运动持续下去,开源理念深入人心,因为高校研究突破也好,因为面向消费者的企业开源基础架构组件也好,因为下一节中要讨论的保护现有软件因此开源抢占标准也好,目前存在的所有专有软件,都会被开源软件所替代。
但是到那个时候,又会有新的商业需求产生,这些需求被开源运动的创造力满足的时间差,是存在提供解决方案的窗口的。世界之大,无奇不有,各种定制化的需求可以是非常特殊或小众的,而开源软件往往只解决主要问题和部分场景。另一方面,数字化进程大跨步前进,哪怕开源软件理论上能够解决好一个问题,但是实际实施的时候,仍然需要专家技术支持,并且维护后续迭代当中可能出现的问题。订阅咨询和解决方案这样依托于开源软件的商业模式,是能够长期存在的。
开源标准以保护现存业务
这种动机只有当企业成长到一定规模的时候才会产生,到这个时候,企业的商业模型往往已经非常复杂,甚至并不只是依靠软件服务来盈利。这种情形可以认为是上一节“商业模型依托于开源软件”的变体,即企业软件生态当中错综复杂地依赖了一系列开源软件,继而主要出于保护现存业务,顺带扩大技术影响力,来以开源软件协议公开企业内部的关键软件,以夺取开源世界对应业务领域的标准。
出于这一动机实践开源的典型企业就是谷歌。无论是 Kubernetes 还是 Istio 的开源,谷歌从中获得的直接商业利润都是不足以促成它做这样的动作的。然而,谷歌通过对自己内部业务应用的分析,看出容器技术和云原生应用是未来业务发展的方向。为了保护公司内部所有基于 Kubernetes 同类云平台的业务能够持续得到新生代工程师的认同和维护,谷歌需要占领云原生标准的话语权。
这里有段逸闻想必同行也耳熟能详,说当初谷歌找上 Docker 希望合作开发容器调度平台,但是 Docker 认为自己单独开发 Docker Swarm 也能赢下容器战争。结局大家也都知道了,Kubernetes 赢下了容器战争,Docker Swarm / Apache Mesos / Open Stack / Cloud Foundry 等等当初的对手则黯然退场乃至彻底死亡。
相关技术被潮流所抛弃对采用这些技术的企业和团队带来的打击是非常严重的。不仅仅是押宝相应技术的团队被市场所否定,就业前景黯淡,对于公司来说,这意味着可能几十万行、上百万行乃至更多的业务代码都成了技术债务。站在今天的角度能够看到的例子,就是欧美国家银行当中海量的 COBOL 语言写成的业务系统,如今能找到的有维护能力的工程师最年轻的也有六十岁以上。如果这个世界上能够维护这些系统的工程师已经绝迹,那么企业的业务就暴露在巨大的风险之下。显然,当初选择了 Docker Swarm 和 Apache Mesos 的企业也将面临越来越招不到人维护的处境。在这种情况下,唯一能做的就是及时将遗留系统迁移到上游标准,但是这样的工作往往需要更加精通被淘汰的技术的工程师才能牵头完成,并且相应的时间精力成本不可估量。如果迁移这么简单,那些 COBOL 代码又是怎么历经几十年都无人能够“迁移”的呢?
不仅仅是容器战争这样出圈的开源标准之争,Yahoo! 开源 Apache ZooKeeper 和 Apache Pulsar 等软件,阿里开源 Apache RocketMQ 和全面投入 Apache Flink 的开发,Netflix 开源 Apache Curator 和 Apache Iceberg 以及 Uber 开源 Apache Hudi 等等,都有保护自己线上业务的动机在里面。当然,如果能够借此机会树立公司的技术品牌,吸纳高水平的技术人才,乃至主导行业未来的发展方向,那就是意外之喜了。
不完全是软件行业为了保护现存业务,在开源技术以争夺行业标准的方向上,还有三个值得一提的案例。
第一个是启发我从这个方向看待企业实践开源的动机的例子。Bjarne Stroustrup 在 2020 年总结 C++ 发展历程的论文 Thriving in a Crowded and Changing World: C++ 2006–2020 当中提到了 C++ 标准委员会当中有许多耳熟能详的大公司的参与,包括苹果、谷歌、英特尔、微软、摩根士丹利、英伟达、高通、红帽和 IBM 等等。每个提案提出的时候,往往代表了某个公司或科研机构经年的努力、实践和生产检验。论文当中回顾了若干提案导致不同硬件厂商的标准之争、大学科研机构的方向之争和软件公司保护现存业务不受完全不同的标准的影响的争论。
例如,各家都有自己的协程实现和用例,如果标准库的实现与自家实现的关键设计和接口不同,那么就意味着以上游的分叉,这将导致上面提到的实现被开源社群所抛弃或者巨大的迁移成本的问题。对于硬件厂商来说,类似于 C/C++ 这样的系统编程语言是硬件接口接入软件层面第一个要打交道的层次。如果在并发语义、时钟接口或者硬件访问标准上采取了一家硬件厂商的方案,那么其他硬件厂商的众多生产流水线就面临立即被市场淘汰的风险,以及成为相应细分领域追随者而不是领导者或公平竞争者的劣势。
第二个是谷歌开源 Android 操作系统的例子。开发和开源 Android 操作系统之前,谷歌内部并没有大量的现存业务。但是众所周知,为了避免移动互联网时代的基础设施移动设备的操作系统被 iOS 全面统治,从而在谷歌和苹果的全面软件技术竞争上处于劣势,后发的谷歌选择开源的方式来开发自己的移动设备操作系统。谷歌在浏览器市场上也采用了类似的模式,谷歌浏览器的内核是开源的 Chromium 项目,这一选择或许受到了世纪初 Firefox 在与 IE 的竞争下赢得巨大成功的启示。不可否认的是,开源的 Android 操作系统形成的庞大生态,开源的 Chromium 内核衍生的一系列浏览器软件,成为了谷歌在这两个方向上核心技术极深的护城河,同时也极大地扩张了这两个领域的市场规模。
第三个例子是跨领域的特斯拉的例子。特斯拉进军新能源汽车领域时,这个领域的市场规模还很有限。即使特斯拉是行业当中无可争议的老大,新能源汽车在行业成熟度,全球化分工的可行性和社会认可度都是极其有限的。通过开源核心基础技术,不追究使用基础专利侵权,使得全球所有看到机会的人才投入到这个行业当中来。行业成熟度决定特斯拉能够持续地招聘到什么水平的人才。如果市场上只有特斯拉一家公司,那么选择这个方向的人心里就要打鼓,现在即使投身这个行业进不去特斯拉,或者特斯拉出现问题要调整或者裁员,也能找到其他岗位继续自己的职业生涯。如此,加上行业热情高涨,社会认可度高,人才投入到这一领域的概率和比例就大大增加了。另一个方面,社会认可度还可以增加大众购买新能源汽车的动力和信心,全球化分工则使得特斯拉的生产制造流水线能够放置到人力成本最经济的国家或地区完成。
企业实践开源的其他收益
前面三段分类讨论了不同商业模型下的企业实践开源的动机和形式的不同,这一段从企业实践开源的收益的角度出发,讨论上面没有专门点出的动机。
内容生产的原材料
定位自己为技术公司的企业,需要解决的一个问题就是如何建立和持续强化技术品牌。技术品牌打造的一个关键支柱是技术内容运营,内容运营最大的挑战是没有内容。巧妇难为无米之炊,如果企业的技术人才、研发部门的日常工作当中没有生产出有利于打造品牌的技术内容原材料,期待运营部门自己凭空创造出内容是非常困难的。
企业以开源文化或者开源办公室为支点,系统地采集员工在上游开源社群或者企业开源的软件社群当中的活动,就能为内容生产提供优质的原材料。例如许多开源社群都会有自己的 Weekly 新闻,记录最近一周开发团队和周边生态发生的要闻,包括实现了什么新功能,修复了什么问题,有哪些新成员加入,软件生态有什么新组件或者老组件的重大变更,社交媒体上有什么与本社群相关的热点。企业鼓励员工积极参与上游开源社群,积极地以开源协同的方式运行企业开源的软件社群,在这个从业者都有旺盛的求知欲和参与热情的行业当中,不难积累出值得宣传的内容。
这些内容都是 WORKING IN PUBLIC 的行为,因此也就不存在是企业“内部”的动作,从而出现茫茫多内容审核的问题。此外,内容运营最能激发参与热情和建立技术品牌的点,在于其他人也能方便地加入进来,验证你发布的内容当中提到的事情是真的,参与到发布的招募事项里面来,亲力亲为与其他社群成员形成联系。
实践软件工程理论
要想从 Apache 软件基金会的孵化器中毕业,成为 Apache 顶级项目,需要在 Apache 成熟度模型的指导下实践一系列软件工程的理论。
对于其他开源社群的建设来说,要想发挥开源协同的最大价值,同样需要在这个远远超出一个公司员工总数量级的开放式环境当中高效地协同不同的参与者。从代码到文档,从开发到测试再到发布,从协议合规到软件安全,从技术社群到开源生态,每一个方面都是对一个新生的开源社群的考验。
尤其是国内短于软件工程理论的交流和实践的环境下,企业鼓励员工参与开源社群,将自己所依赖的不构成明显商业竞争优势的专有软件开源并尝试建设一个开源社群,是一个很好的与全球同行切磋“高质量软件应该怎么制造”的路线。企业需要懂得软件工程的员工来做好自己需要的业务软件和基础软件,而缺乏现成可参考的案例和可以试手的对象,不仅对于学生是个问题,对于不像谷歌那样有一套完整的软件工程体系和大量可供参考和参与的软件的公司的员工来说,也是个巨大的问题。
许多程序员不知道文档应该怎么写,许多程序员没见过复杂的并发问题,许多程序员不了解软件构建的过程,对软件整体的交付流水线知之甚少,更有许多程序员不知道如何与其他成员沟通协作、合作开发。对这些全局视角和具体细节把握的不足,软实力的缺失,就是程序员能力的短板,虽然不是每个人都要是全面的人才,但是这应该是每一个从业者追求的目标。这些问题,只要你深入参与到开源社群当中去,或者自己运行一个开源社群,其实就有机会积累到宝贵的经验。
至于前文已经提过的建立技术品牌以后,带来的招聘上和客户取信上的收益,赢得开源标准带来的一系列价值,这里就不再赘述。
总结
根据企业商业模式与开源软件之间的关系,其实践开源的动机与具体实施的行为会有不小的差别。
我认为,直接销售开源软件终将被证明是不可行的。基于开源软件,提供订阅服务或技术支持,构建企业级的解决方案,是能够长久存续的商业模式,也因此提供了企业长期实践开源的源动力。当企业逐渐发展以形成复杂的商业模式以后,开源就不仅仅是技术影响力或者协同开发这么纯粹了。主动参与自己所依赖的开源软件的上游社群,或者以各种方式支持上游社群的发展,争夺开源标准,保证自己的现存业务在激烈的市场和技术竞争下能够长期存在,直到领域的终局,也是这一阶段的企业需要考量的动机。