Apache 开源社群的“石头汤”
《程序员修炼之道》讲了一个有趣的“石头汤”寓言。这个寓言里,饿着肚子的外来人在村子里烧了一锅水,放了三块石头,开始煮“石头汤”。这样的行为引来好奇的村民围观,外来人顺势在“石头汤”的基础上引导村民们添加食材以改善这锅料理。最后,村民和外来人一起煮出了一锅靓汤,外来人于是把石头从汤里扔掉,所有人分享了这顿美餐。
开源协同的工作方式与制作“石头汤”的方式有些相似。开源社群的核心成员与寓言中的外来人一样,充当了催化剂的角色,将这些各自拥有不同背景的人群组织起来。这样,社群成员才能聚在一起做出他们单独无法做到的事情。最后,所有人都是赢家。
当然,在这个版本的“石头汤”寓言里,村民被外来人骗了,石头并没有为最终的美味产生直接价值。《开放式组织》指出这种行为是一次性的,并且价值仅仅单向地从村民一方流向外来人一方,以至于它被冠以“汤姆·索亚合作模式”的恶名。
开源协同的模式保留了“石头汤”寓言当中催化剂的内核,但是这一次,外来人提供的不是水煮石头,而是初具规模的汤底和食材。《大教堂与集市》在揭示集市模式的必要条件时阐述了这一点,这个隐喻意味着一个能运行的软件,并且让潜在的合作开发者相信,这个软件在可以预见的未来,能够演变成一个非常棒的东西。
Apache 开源社群由三百多个项目组成,其中不乏开源版本“石头汤”的现实案例。
Apache Hudi
Apache Hudi 就是这样的一个例子。实际上,就是近期几次引用 Hudi 的例子说明开源协同的工作机制的经历才促使我写这篇文章。
如果用一句话介绍 Hudi 的第一个版本做的事情,那就是写一个 Spark 程序,把数据从 HDFS 读出来,根据用户通过 upsert 接口传入的数据更新请求修改数据,然后写回到 HDFS 上。
就这么简单?
就这么简单。
众所周知,HDFS 的文件不支持随机读写,而数据分析的流水线上需要更新历史数据是个客观存在的需求,各个公司里同类型的 Spark 程序或者不用 Spark 实现相同功能的程序实现过许多遍了。这样的功能做一个平凡的实现,甚至有经验的工程师不出数日就可以写出来。
那么是什么让 Hudi 与众不同呢?答案就在“石头汤”的寓言里。
Hudi 的主要作者,也是现在项目的 PMC Chair Vinoth 敏锐地察觉到了这个需求的普遍性,并且相信跳出公司的局限,集合整个开源共同体的力量开发这样一个公共的需求对项目而言是最好的选择。因此,他推动 Hudi 项目从 Uber 公司的内部作品捐赠给 Apache 软件基金会,借助 Apache 的平台向每一个实现同类功能的开发者发出邀请参与协同。
虽然前面介绍 Hudi 的功能非常简单,但是其实从 Hudi 进入孵化器的提案当中可以看到,它在一个平凡的 Spark 程序以外,还实现了和当时的大数据生态的初步整合,可以通过 Hive 等现成方案和 Hudi 生产的数据进行交互,这就意味成熟的大数据生态和各种工具可以迁移到 Hudi 的用例上。
这两点对于一个新项目来说是至关重要的。如果没有可行的软件,只是一个想法,那么相比那么多公司内部实现的同类型程序,一个大家都能想到的想法毫无价值。如果作为一个大数据领域的解决方案,不能和大数据生态融合,那么没人会相信它能拥有光明的未来,大部分开发者会持观望态度而不是花费自己宝贵的时间参与协同,因为有这时间还不如改善自己已经实现的同类型程序。
然而 Hudi 做到了起步阶段这个小小的身位领先,并且紧紧围绕着用户需求开发功能、打磨产品和吸纳贡献。既然 Hudi 已经做好的工作我要花费数月才能追上,尤其是其中还包括了许多我不愿意做的“脏活”,那么我为什么不把自己想要实现而 Hudi 尚未支持的功能直接在上游实现呢?反正 Hudi 是 Apache 社群的项目,向上游做出的贡献我自己仍然能够随时用于任何目的。
这样的想法在 Hudi 项目孵化早期推动了诸如 @vinoyang 和 @leesf 这样的开发者的参与。他们在 Hudi 的稳定性和可用性上做出了显著的贡献,而秉承开放和合作的理念的 Hudi 社群也很快吸纳他们成为项目 PPMC 的成员。
Hudi 相对于其他方案的小小优势,加上社群做出这样的表态,以实际行动实践开源社群 Meritocracy 的原则,很快聚拢起来一批有实力的开发者参与其中。这样的正向循环让一开始的小小优势逐渐扩展成今天数据湖领域相对于大部分其他解决方案明显的领先,这也进一步地让领域中潜在的用户和开发者被吸引到 Hudi 社群当中来。
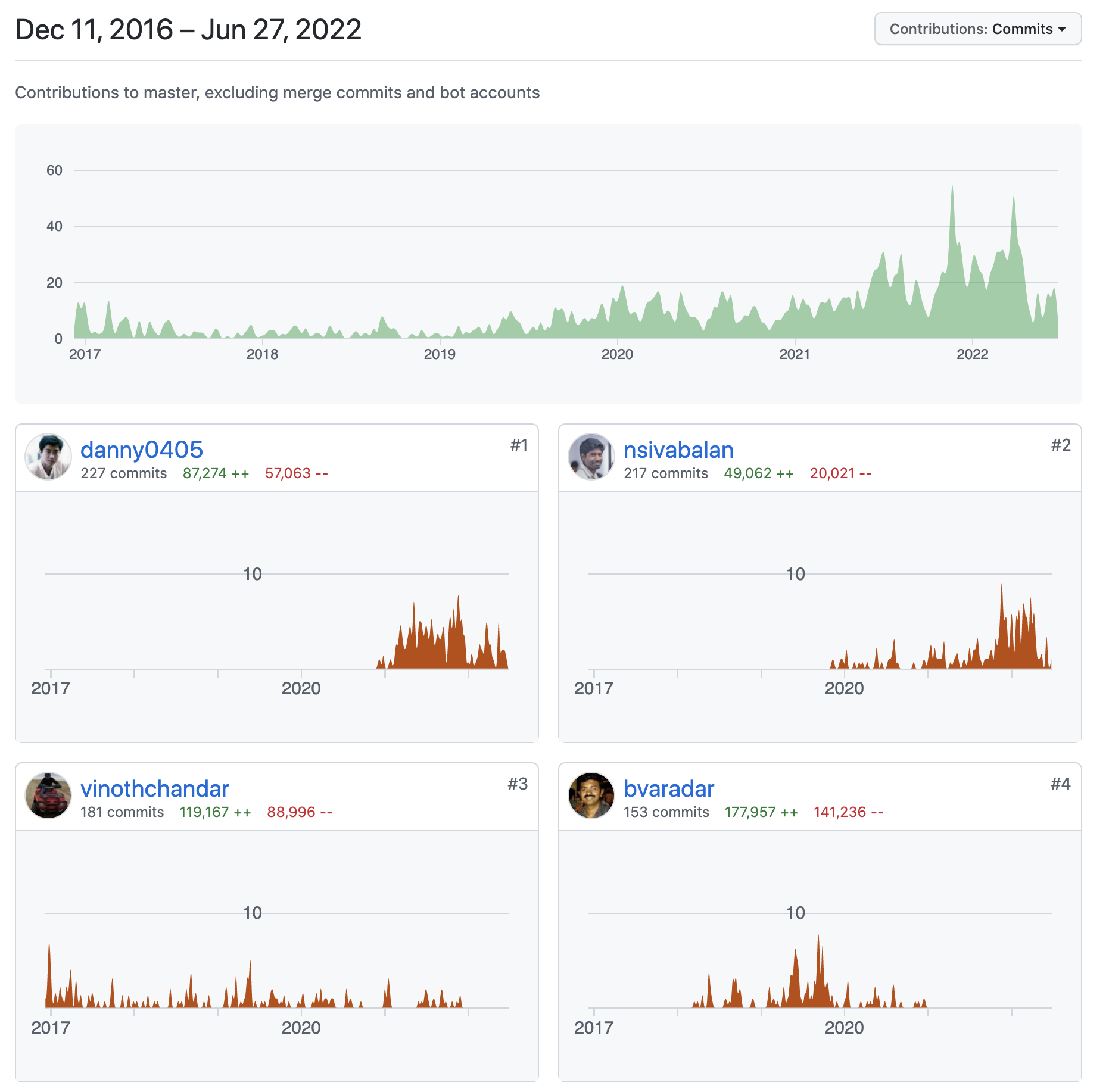

来自 T3 出行的开发者写出了 Flink on Hudi 的方案与最初实现,来自阿里巴巴的开发者将其完善到生产可用并且具有竞争力。新的 RFC 正在路上,实现一个 Hudi Server 来以内存状态读写取代目前开销显著的元数据文件读写,实现 Record 级别的 CDC 服务等等。数百个将自己的聪明才智和宝贵的时间投入到让 Hudi 变成一个更好的开源软件的参与者,组成了 Hudi 3000 个提交里一点一滴的改善。这正是“石头汤”里村民们从家中带来各自的食材,最终做出一锅美味的翻版。
这样的案例在 Apache 当中并不是唯一的。
Apache BookKeeper
Apache BookKeeper(BK) 从代码角度最早可追溯到 2008 年,当时的它是 Yahoo! 巴萨罗那研究院的研究项目。起初,其首要目的是解决 HDFS NameNode 的可用性问题,后来成为 Apache ZooKeeper 的子项目。2014 年年底从 ZooKeeper 社群孵化成为顶级项目。
BK 完全对等节点的设计使得它被许多寻找分布式日志存储系统的团队所青睐,进而被广泛使用在多个公司的不同场景当中。
- Diennea 的工程师在开发 HerdDB 时使用 BK 存储预写日志。
- Twitter 的工程师基于 BK 创建了 DistributedLog 项目,后者在 BK 上层封装了面向终端用户的分布式日志接口。后来,这个项目被合并回 BK 社群成为一个子项目。
- Dell EMC 的工程师基于 BK 创建了 Pravega 项目,旨在提供流式数据的存储。目前是 CNCF 的沙箱项目。
- Yahoo! 的工程师基于 BK 创建了 Apache Pulsar 项目,它是一个能够同时支持 RabbitMQ 式的消息队列语义和 Apache Kafka 式的消息流语义的云原生消息平台。
- 后来,这个项目的创始成员成立了 StreamNative 公司来提供企业级的 Pulsar 服务。
- 另外一家企业服务公司 DataStax 使用 Pulsar 来补齐其商业产品 AstraDB 在数据同步和数据变更订阅上的短板。
- StreamNative 围绕 Pulsar 发起的 Kafka on Pulsar 项目吸引了来自腾讯和 DataStax 等公司的开发者的参与。
围绕着 BK 形成的庞大生态持续反哺着 BK 社区,使其在十多年后仍然能够保持强大的生命力和迭代活力。同时,虽然社群当中存在着不同公司背景的参与者,但是 Apache 的开源之道将所有参与者都认为是个体参与者,并且强调社群独立于其他组织影响的中立性。BK 社群和 Pulsar 社群都坚持了这样的原则,因此社群成员无论是什么背景,大都能够和谐友好地相处。
“石头汤”的寓言不只有开始的石头与结尾的美味,重要的是如何促使这个变化发生的过程。BK 和 Hudi 相同的地方,在于社群维护者都在初始项目解决了一个特定问题的基础上,向社群抛出自己合理的请求,然后不断完善。无论是来自用户需求的反馈,还是工程师设计的方案,一旦有成果产出,社群维护者会及时发布新版本以鼓励做出贡献的参与者并向全体社群成员展示最新的进展。
在这之后,社群维护者引导或者社群成员自发地提出“这个软件还可以更好,只要我们再完成……”的想法,就能清晰地在开发者当中传达出下一步可以做什么的信息。具体的待办事项好过一个模糊的愿景,开源共同体的开发者几乎总是倾向于加入到一个推进中的成功项目,而不是一个刚有设计的项目。架构设计和第一个版本是项目创始团队的责任,这也是开源协同与原版“石头汤”寓言的重要不同:如果你只是丢出两块石头,不会有参与者能够从无到有开发出整个开源软件。
Apache Kvrocks
Apache Kvrocks 是今年四月份进入 Apache 孵化器的项目,我是这个项目孵化期导师的一员。最后我想从这个项目出发,具体讲一个引导“村民”向“石头汤”当中添加“佐料”的例子。
Kvrocks 是一个 Redis 协议兼容的分布式 KV NoSQL 数据库,不同于 Redis 采用全内存存储,Kvrocks 的存储是基于磁盘的。不同于企业放弃维护后捐赠给开源社群的项目,2019 年发起自美图基础架构团队开发的 Kvrocks 早在 2020 年就开始以开源项目的形式运作,历经一年多的发展吸引到了来自百度和携程等公司的开发者的参与,并在国内外多家公司的生产环境上线部署。
上面这篇 Kvrocks 发布的加入 Apache 孵化器的文章当中几次提到,社群维护团队选择加入 Apache 的核心原因是“建立更大和多样化的开发者社区”。事实上,Apache 开源之道的指导和 Apache 品牌的帮助确实为 Kvrocks 打开了一个新的大门。
我在成为 Kvrocks 项目的导师之后,自然而然地参与到项目社群当中。如同这条推文提到的,接触一个新的开源项目,第一步就是克隆代码并尝试构建。我在构建过程 Kvrocks binary 当中发现了项目 CMake 脚本存在优化空间。这个时候,我想起来在《CMake 是怎么工作的?》文章评论区里 @PragmaTwice 分享了他使用 CMake 的一些经验,正好跟我想做的改进相符合。因此,我邀请他把他的经验实践在 Kvrocks 项目上。
很快,Twice 在我和 Kvrocks 的主要作者 @git-hulk 等人的帮助下系统地改造了基于 CMake 的构建逻辑,取代了此前 Git Submodule + Makefile 的方案。此外,Twice 出于自己对 C++ 编码实践的理解,在阅读源码的过程中发现了许多“这个软件还可以更好,只要我们再完成……”的点子。遵循开源社群一直以来的协同惯例,他把这些想法发布成若干个 issue 并自己开始实现。就在最近几周,他所发起的工作吸引到了更多开发者的参与。
- Tracking issue for build system enhancements
- Proposal: Just return values instead of passing pointers if possible
- Use unique_ptr to eliminate some trivial manual deallocation
Apache 孵化器的主席 Justin Mclean 总是建议孵化期项目在参与者做出具体贡献之后尽快授予他们 Committer 身份,以鼓励人们持续做出贡献。他所理解的 Apache 之道应该关注到绝大部分参与者的情况,出于时区、本职工作和陪伴家人等等原因,参与者并不总是全力为某个开源项目工作。
Kvrocks 的 PMC 成员基于这样的认识,结合 Twice 在六月上旬时已经完成的工作和表现出来的能力水平,经过 Apache 社群议事的标准流程投票通过邀请 Twice 成为 Kvrocks Committer 的一员。成为 Kvrocks Committer 之后至今的两周里,Twice 在保持原本的参与水准之外,更加积极地 review 其他社群成员的补丁,并协调不同 pull request 和合并参与者贡献的代码。
可以看到,Apache 开源社群激励参与者共同制作“石头汤”的具体方式,就是以参与程度和具体贡献回馈参与者相应的声誉和权威。
总结
软件行业的经典著作《程序员修炼之道》描述了一个“石头汤”的寓言,在开源社群当中也存在着类似“石头汤”的协作流程。不同于原始版本多少带点欺骗的味道,开源协同的模式强调最初的软件本身即是一个可用的软件。而与原始版本相同的是,开源协同与外来人制作“石头汤”时采取的策略重点都在于做推动变革的催化剂。
开源软件的维护者们也可以借鉴“石头汤”的魔法,在一个基本可用的软件的基础上,抛出可以做的更好的可能性,身体力行并团结潜在的开发者一起不断实现做出的预言,最终为行业制造出一个高质量的开源软件。