如何构建一个受保护的网站
前段时间,我出于兴趣试着做了一个需要登录鉴权才能访问的个人网站,最终以 Docusaurus 为内容框架,Next.js 做中间件,Vercel 托管网站,再加上 Auth0 作为鉴权解决方案,实现了一个基本免费的方案。这里做一个分享。
基本的目标是发布一系列文字内容为中心的网页,并限制访问这些页面必须先鉴权同时确认身份信息在白名单上,防止被任意用户访问或黑客破解。
从这个角度看,鉴权的功能实际上是一个包装层,首先要解决的是内容生产的问题。由于我最近主要开发的网站,包括 Pulsar 官方网站和开源小镇都是用 Docusaurus 生成的。所以这部分的选型,我就直接选定了 Docusaurus 框架,不再赘述。
实际上,“网页”也不是一个强需求,如果能很好的生成带水印或加密的 PDF 文件,也是一种解决方案。我于是调研了 Pandoc 和 Sphinx 这两种工具,但是它们都有自己的学习成本,并且生成 PDF 基本要先走一遭 Latex 的生态,实在是折腾不来,最终放弃。
选定 Docusaurus 以后,我就开始折腾起了鉴权的问题。
由于实在不想自己折腾一个服务器,加上之前一直是用 Vercel 来托管静态网站,我首先考虑在能够开放源码和内容的托管 Docusaurus 框架生成的网站的基础上,加上 client-side 的保护。
Attempt: Client-side 的鉴权方案
要做具体的鉴权方案,首先要考虑的是选择哪个鉴权软件或解决方案。由于 Vercel 的模板有 Auth0 的示例,加上 Auth0 确实上手非常快,所以我很快选定了 Auth0 作为解决方案。从结果来看,这个选择也是很合理的。
中间我还调研尝试过 Supabase 和 Logto 等解决方案。但是 Supabase 实在是太复杂了,开发者体验非常差;Logto 还没有供应商提供 SaaS 服务,我不太可能再去折腾一套部署,否则为什么不用 Apache Web Server 或者 Nginx 里面写点逻辑呢?
Auth0 client-side 的鉴权,结合 Docusaurus 基于 React 框架开发,可以找到 @auth0/auth0-react 集成库,对应的方案大致如下:
1 | // src/theme/Root.tsx |
上面这段代码有很多细节,但是核心是用 Auth0Provider 组件把 Docusaurus 的页面元素全部包括进来。这样,浏览器访问对应页面的时候,得到的就会是一个自定义的 Authenticator 生成的页面,比如在这个尝试里,我把它做成一个带有 LOGO 和登录按钮的页面:
1 | export default function Authenticator({children}): JSX.Element { |
但是,这样的方法会有两个问题。
第一个问题相对好解决,记录在 easyops-cn/docusaurus-search-local#210 上。由于生成的页面内容 HTML 文件里全都是登录页,所以这里提到的本地搜索插件建立索引的时候就无法取得正确的内容。
对于 Algolia 这样的搜索专业解决方案来说,它会提供爬取 bypass 的途径,用户配置鉴权过程的 client secret 就可以正确获取页面内容。
对于依赖 HTML 文件内容的本地搜索插件来说,最终我选择的解决方案是上面代码里 BUILD 配置体现出来的两阶段构建。第一次先把 Auth0Provider 的逻辑给禁用掉,生成包含内容的 HTML 文件,以此继续生成正确的 search-index.json 索引文件。把这个文件拷贝出来,启用 Auth0Provider 再次生成网站,再用拷贝出来的索引文件覆盖这次生成的无效索引文件,就可以绕过这个问题。
第二个问题就不好解决了。在解决第一个问题的时候,我尝试了这样一个解决方案:
1 | import useIsBrowser from "@docusaurus/useIsBrowser"; |
这样,因为 isBrowser 在构建阶段一定是 false 所以生成索引正常工作。实际访问的时候,isBrowser 变成 false 于是用户会被导向登录页。
但是,熟悉 React 的同学应该可以看到这里一个明显的问题。isBrowser 被设置成 true 要在 React 渲染逻辑加载完毕之后,所以用户会有一个明显的先能访问页面,然后被弹出去要求登录的体验。
更加要命的是第一次访问的时候其实已经把页面内容发送到浏览器了,随后弹出去的逻辑只是 JS 代码的逻辑。这样,只要知道从开发者工具里捞传输内容,甚至直接用 wget 或者 curl 等工具访问页面的用户,就可以得到页面的源代码,从而知道页面的内容。
即使不用 isBrowser 的方案,回到两阶段构建的方案,也会有类似的问题。
这一次,在用户鉴权之前,他只能看到登录页,没法接收到实际页面的内容。所以这个路径上是被很好的保护的。但是,我的好奇心让我不由得探究:如果页面上没有实际内容,那么用户鉴权之后到底是怎么看到实际内容的呢?
怀着这样的疑问,我在 docusaurus 的论坛上发起了一个讨论。最终,我发现了实际内容被编码到 JS 文件里,鉴权成功后时间内容会从 JS 文件里被调用加载上来。
这里就有一个问题了。JS 文件作为静态文件,也是被托管到 Vercel 的服务器上的,只要有路径,谁都可以访问。而且访问静态资源不会走 React 框架的逻辑,自然也就没什么鉴权的说法。实际上,我在未鉴权的情况下,直接访问 JS 文件是可行的。
那么问题就是用户能不能知道 JS 文件的路径是什么呢?Docusaurus 生成的 JS 文件,是十六进制的数字编号,并没有什么特别的规律。如果用户在正常情况下无法轻易破解 JS 文件路径,那么这个解决方案也是可行的。
可惜的是,我自己在知道框架工作逻辑的情况下,不到半个小时就破解了这个规律。实际上,就算只访问登录页,也可以看到引用了一个带 runtime-main 字样的 JS 文件。打开这个文件,找到固定特征位置的 content files 映射表,取出两个分段里相同的键对应的值 $a 和 $b 再拼成 $a.$b.js 就是对应内容的 JS 文件。这样,随便写个爬虫就可以把页面内容全爬下来了。
虽然对于文本内容的读者来说,大部分是不会做也不知道可以做这样的事的,但是我强迫症上来了,就总想着找个更干净的解决方法。
有读者可能会问,既然如此,鉴权软件提供这种集成有什么用呢?实际上,鉴权(Authentication)和授权(authorization)是不一样的。鉴权主要是解析用户身份,获取对应的用户信息,也就是访客是谁。对于任何人都可以访问的页面来说,也有根据访客身份做定制化展示的需求。相反,授权是在取得用户信息之后,判断对应用户是否具有访问对应资源或执行对应操作的过程。因此,哪怕不做权限控制,只是支持用户登录获取用户信息,也是有价值的。
Vercel Edge Middleware
可以看到,只要试图在 client-side 解决问题,就一定解决不了访问静态资源无法保护的问题,因为访问静态资源的整个逻辑根本不走用户定义的 JS 代码,而是由服务器完成的。实际上,用户访问网页,也是服务器把对应的静态资源返回给浏览器,浏览器加载对应逻辑渲染得到的。
要想拦截这个过程,只能在 server-side 处理入站请求的时候动手脚,这也是 Docusaurus 的主要维护者 @slober 在上面讨论中的建议。由于我不想自己维护服务器,而且已经多次将网站托管在 Vercel 平台上,这个生态相对比较熟悉,于是我先尝试寻找 Vercel 平台提供的解决方案。
幸运的是,Vercel 提供了 Edge Middleware 的方案来支持这类需求。
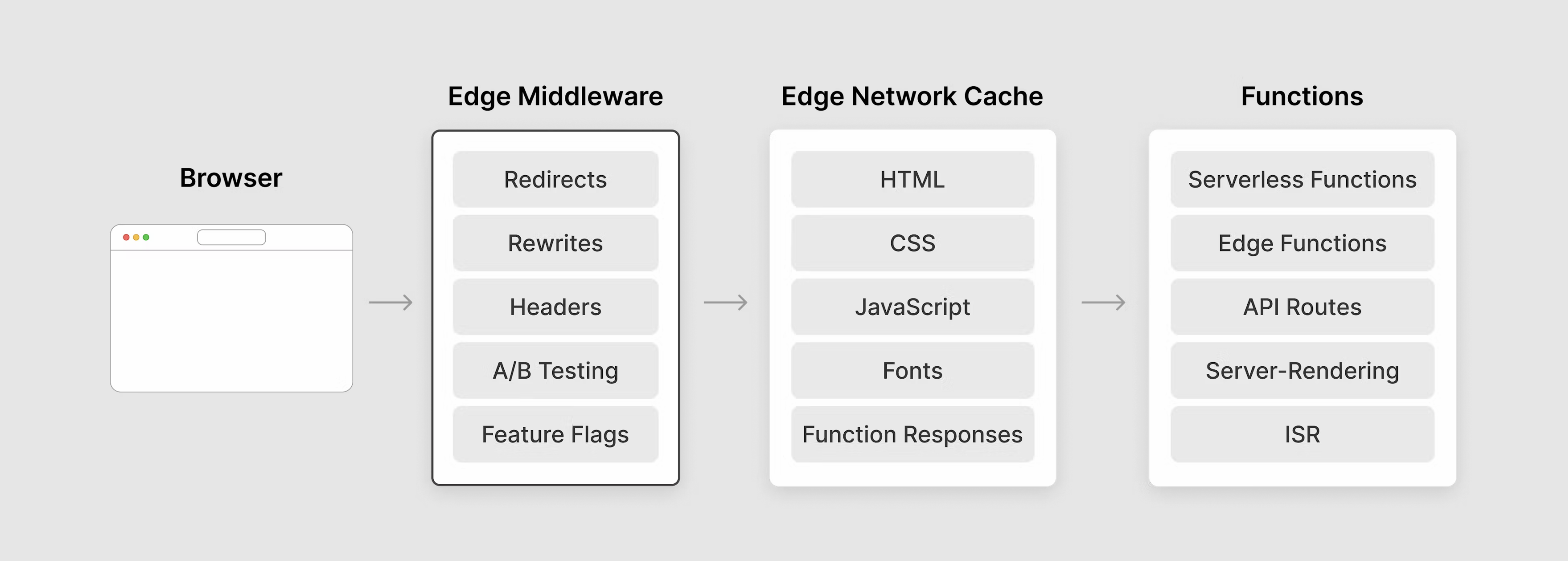
上图展示了 Edge Middleware 在 Vercel 平台上的位置:浏览器的请求首先会经过 Edge Middleware 处理,再被转发到实际托管资源的服务器进程上。
这样,我就可以在最前面拦截所有针对内容的请求,重定向到鉴权页面,在鉴权返回以后根据用户信息做权限验证,只放过在白名单上的用户。
不过,实际实现的时候又遇到了很多问题。
第一个问题是 Edge Middleware 对框架的差别待遇。
上面 Edge Middleware 的文档页上说明了,针对 Next.js 框架和其他框架托管的网站,能够使用的 Edge Middleware 的功能是不一样的。简单来说,只有在 Next.js 框架下才能使用 Next.js 的 Request/Response 等 next/server 包里的定义。如果强行在 Docusaurus 里使用,会直接报错无法渲染。
这样一样,Auth0 针对 Edge Middleware 的集成 @auth0/nextjs-auth0 就不能用了,因为它依赖了 Next.js 定义的 Request/Response 接口。
有读者可能会说,这样的话 fallback 到 auth0.js 手写一个集成不就好了吗?
一方面,手写一个这样的集成还是很麻烦的,尤其是写对 session cache 那一大坨逻辑,以及手动解析各种 wire protocol 传输的数据,非常枯燥。我是终端用户,我的目的是拿好趁手的工具尽快解决我的问题,而不是跑偏去做一个我的依赖项,除非实在是无路可走。
另一方面,即使想要这么做,Edge Middleware 在 Docusaurus 框架的集成上还是有奇怪的问题。
这一度让我考虑完全切换到 Next.js 框架下,随便找个内容渲染框架把内容丢上去算逑。于是我就遇到了第二个问题。
第二个问题是 Auth0 的 Next.js 集成默认 bypass 了对 Next.js 静态资源的鉴权要求。
或许这里有一些前端的哲学,但是我的需求确实被阻碍了。
有些开发者可能会说,静态资源就是可以被随意访问的,如果你的资源需要被保护,那可以用一个后端服务保护,或者丢到数据库里要求带着账号密码访问。但是我的一个基本诉求就是尽可能不要自己维护一个服务器。如果说这话的人能帮我像在某电商公司那样给我提供网关服务和数据库服务,接我的需求帮我解决,那我自然很乐得按照这种分工方案来实施。
我在 nextjs-auth0 的仓库里记了一个报告,但是看起来维护者不是很能理解我的需求。所幸最后我也没用 Next.js 的解决方案,静态文件路径不在被硬编码 bypass 的 /_next 路径下,也就没了这个问题。
Docusaurus + Next.js 的最终方案
出于以上问题的考虑,加上 Next.js 原生的内容渲染框架实在是没有跟 Docusaurus 能打的选择,最终我选择的是 Docusaurus 框架生成静态网站,然后用 Next.js 框架托管这些静态文件的方案。这样,就能跟 Next.js 生态的其他插件尤其是 @auth0/nextjs-auth0 集成上了。
实际项目结构说来也简单:
1 | . |
核心构建逻辑如下:
1 | pushd ./source |
其中 Docusaurus 框架管理的 source 目录按照正常 Docusaurus 网站的方式开发。Next.js 框架管理的 gateway 目录,需要提供 Auth0 集成的两个文件。
第一个是创建 pages/api/auth/[auth0].js 文件以支持 Auth0 的鉴权流程的一系列 API 接口,默认会生成以下端点:
/api/auth/login/api/auth/logout/api/auth/callback/api/auth/me/api/auth/401
为了处理用户鉴权成功但是权限验证失败的情况,我加了一个 /api/auth/403 端点,最终代码如下:
1 | import { handleAuth } from '@auth0/nextjs-auth0'; |
第二个是创建 middleware.ts 文件定义中间件处理逻辑:
1 | import {getSession, withMiddlewareAuthRequired} from "@auth0/nextjs-auth0/edge" |
除了检验鉴权后用户的访问权限,还有就是处理 Docusaurus 生成的页面,变成 Next.js 的静态资源以后,首次加载如果不是直接访问 HTML 文件,会因为误入 Next.js 框架的解析逻辑而 404 的问题。
具体配置 nextjs-auth0 集成的方法,可以参考官方文档示例。虽然有上面提到的静态文件被无情 bypass 的设计问题,但是总的来说这个集成的文档体验是相当好的。
最终效果,是当你访问任何受保护链接(即除了几个鉴权相关 API 端点以外的链接,包括静态文件)的时候,都会被重定向到 Auth0 提供的鉴权登录页,成功登录后会根据你是否在用户白名单上,分别导向实际页面内容,或者 403 页面。出于内容保护的考虑,这里就不插入对应的动态图演示了。
最终费用是 $0 开销。
应用框架是开源的,无需付费。Vercel 的免费计划对于个人网站来说完全够用,Auth0 的免费额度也是没什么问题的,主要限制在只支持两个内置集成,我实际也只需要 GitHub 和 Google 这两个,甚至只要 GitHub 也行,这样就没有付费的理由了。
Bonus: Logout Button
大家司空见惯的登出按钮其实也是需要开发的。否则一旦成功登录,除非你知道登出的 API 接口是啥,Session 记录会让你在清理缓存之前永远也无法退出。
Docusaurus 最适合做登出按钮的位置就是导航栏右上角,但是 Docusaurus 的导航栏是框架内定义的,预定义的类型里没有点击按钮回调的类型,只有点击图标跳转页面的能力。
一开始,我做了一个点击登出图标后跳转到登出页面,在登出页面里做了登出按钮,但是这个体验就很别扭。所幸我发现了 Docusaurus 上游针对自定义导航栏项目的没有记录在文档的支持,做了一个流畅的登出按钮。
相关代码如下。
第一步,需要定义好登出按钮的组件:
1 | // @site/src/components/LogoutButtonNavbarItem |
内容没有太多好说,为了在展示上跟点击图标有一样的样式效果,内容基本是抄的内置 DefaultNavbarItem 组件的逻辑。功能上,通过访问 /api/auth/me 端点来确认是否是用户登录状态。
第二步,将组件挂载到导航栏项目登记表里:
1 | // @site/src/theme/NavBarItem/ComponentTypes.tsx |
这里,src/theme 是个特殊路径,会覆盖 Docusaurus 框架对应路径的主题组件,对应功能文件在此。
最后,将注册名为 custom-logout-button 的导航栏组件添加到站点配置文件里,注意自定义导航栏组件注册名必须以 custom- 开头:
1 | // docusaurus.config.js |
这里唯一没有提供源码的是关联到样式类型 header-logout-link 上的登出按钮样式,这个可以在网上找到自己喜欢的 SVG 图片用一下的方式添加到 src/css/custom.css 文件:
1 | .header-logout-link:hover { |
Bonus: SVG Editor
编辑 LOGO 和按钮 SVG 文件的时候,深深感受到了一个好的 SVG Editor 的价值。别的也不多说了,上连接:
- Mediamodifier’s Free SVG Editor: https://mediamodifier.com/svg-editor