从参与 Rust 标准库开发看开源贡献的源动力
首先介绍一下我在 Rust 标准库当中做的两个微小的工作。
第一个是从去年 8 月 14 日发起,今年 4 月 6 日合并,历时约 8 个月,目前仍在等待 stabilize 的为 OnceCell 和 OnceLock 增加新接口的提案:
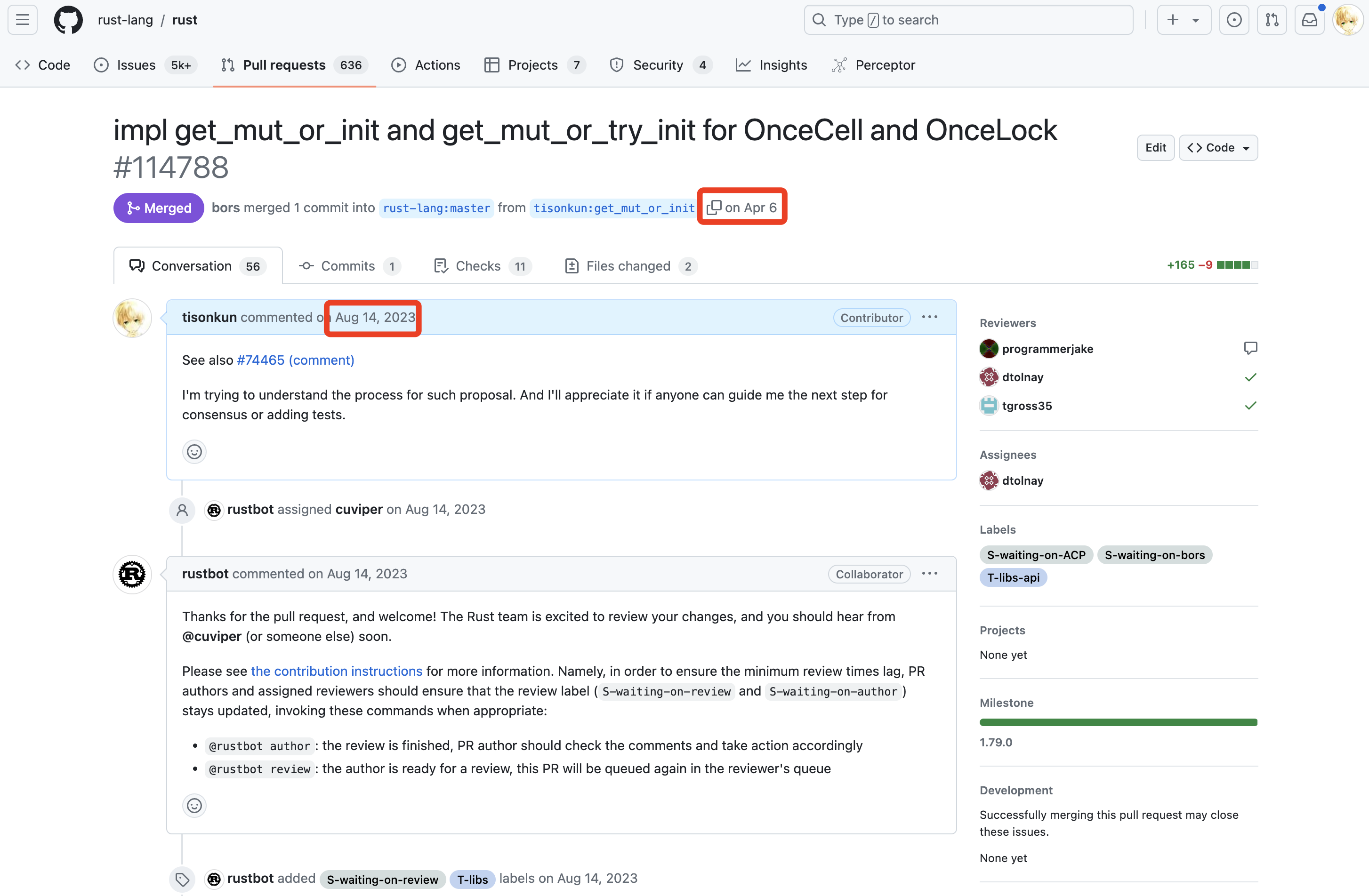
第一次贡献成功合并后,马上第二个工作是从今年 4 月 8 号开始,7 月 6 号合并,历时约 3 个月,同样还在等待 stabilize 的为 PathBuf 和 Path 增加拼接扩展名新接口的提案:
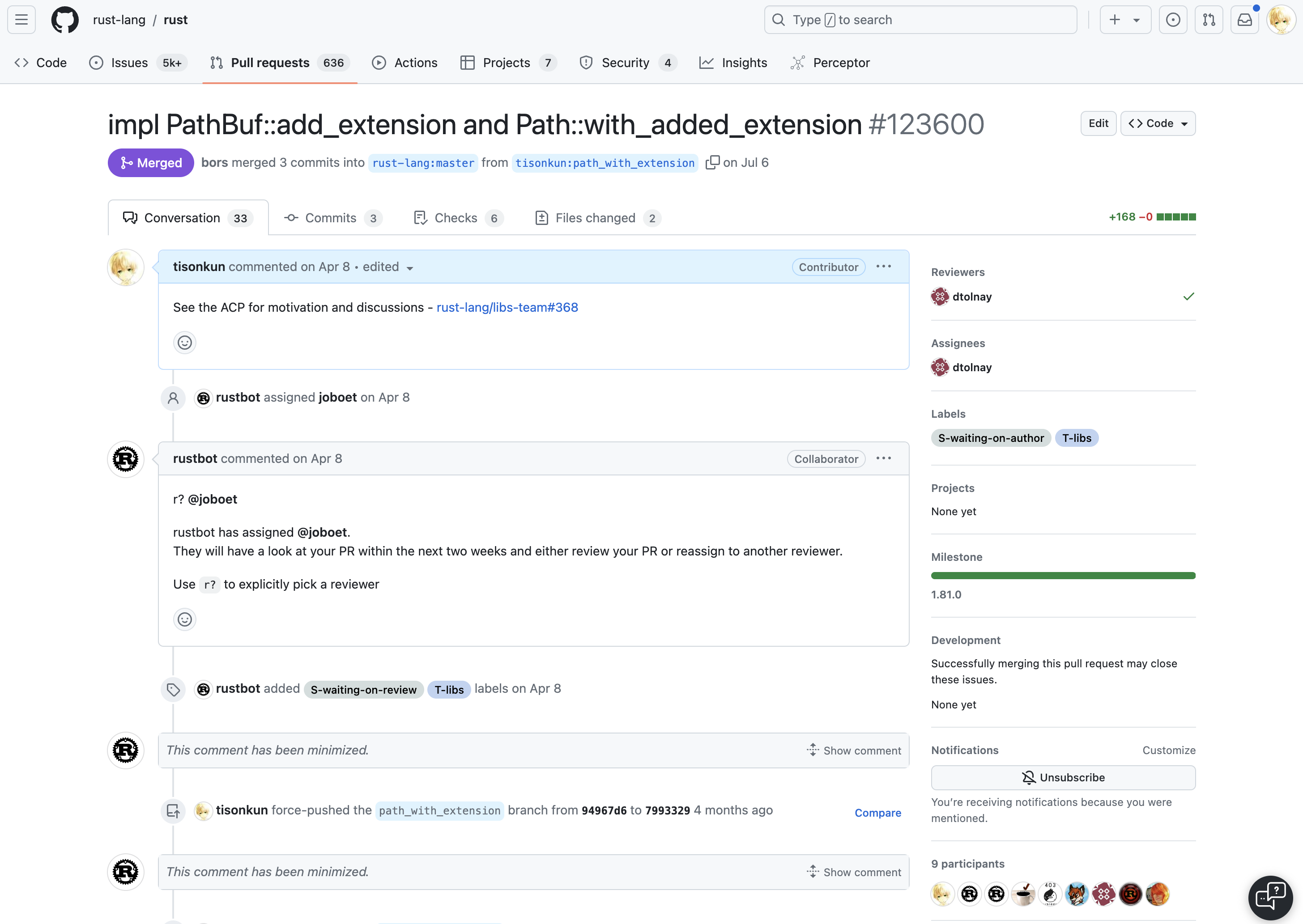
可以看到,这两次贡献的内容可算是同种类型的,第二次提交从发起到合并的时间比第一次缩短了一半以上。本文先介绍 Rust 标准库提案的基本工作流程,然后介绍这两个贡献背后的故事,最终讨论开源贡献的源动力从何而来。
Rust 标准库提案的工作流程
标准库的贡献有很多种,上面我所做的两个贡献都是扩充现有数据结构的接口,也就是 API Change 类型的提案。
Rust 社群为 API Change Proposal (ACP) 设计了专门的流程,流程文档记录在 std-dev-guide 手册中。
简单来说,一共分为以下三个步骤:
- 在
rust-lang/libs-team仓库中创建一个新的 ACP 类型的 Issue 开始讨论; - 讨论形成初步共识以后,修改
rust-lang/rust仓库中标准库的代码并提交 PR 开始评审; - 针对实现达成共识以后,在
rust-lang/rust仓库中创建对应的 Tracking Issue 并由此获得标注 unstable feature 需要的参数(Issue 编码);PR 合并后,由 Tracking Issue 记录后续的 stabilize 流程。
不过,其实我所做的两个简单改动并没有严格遵循这个流程。因为我首先不知道这个流程,加上实际改动的代码非常少,我是直接一个 PR 打上去,然后问一句:“老板们,这里流程是啥?我这有个代码补丁还不错,你看咋进去合适。”
开源贡献的源动力从何而来
为什么要给 OnceCell 和 OnceLock 加接口?
真要说起来,给 OnceCell 和 OnceLock 加接口的起点,还真不是直接一个 PR 怼脸。上面 PR 截图里也能看到,首先是我在原先加入 once_cell 功能的 Tracking Issue 提出为何没有加这两个接口的问题:
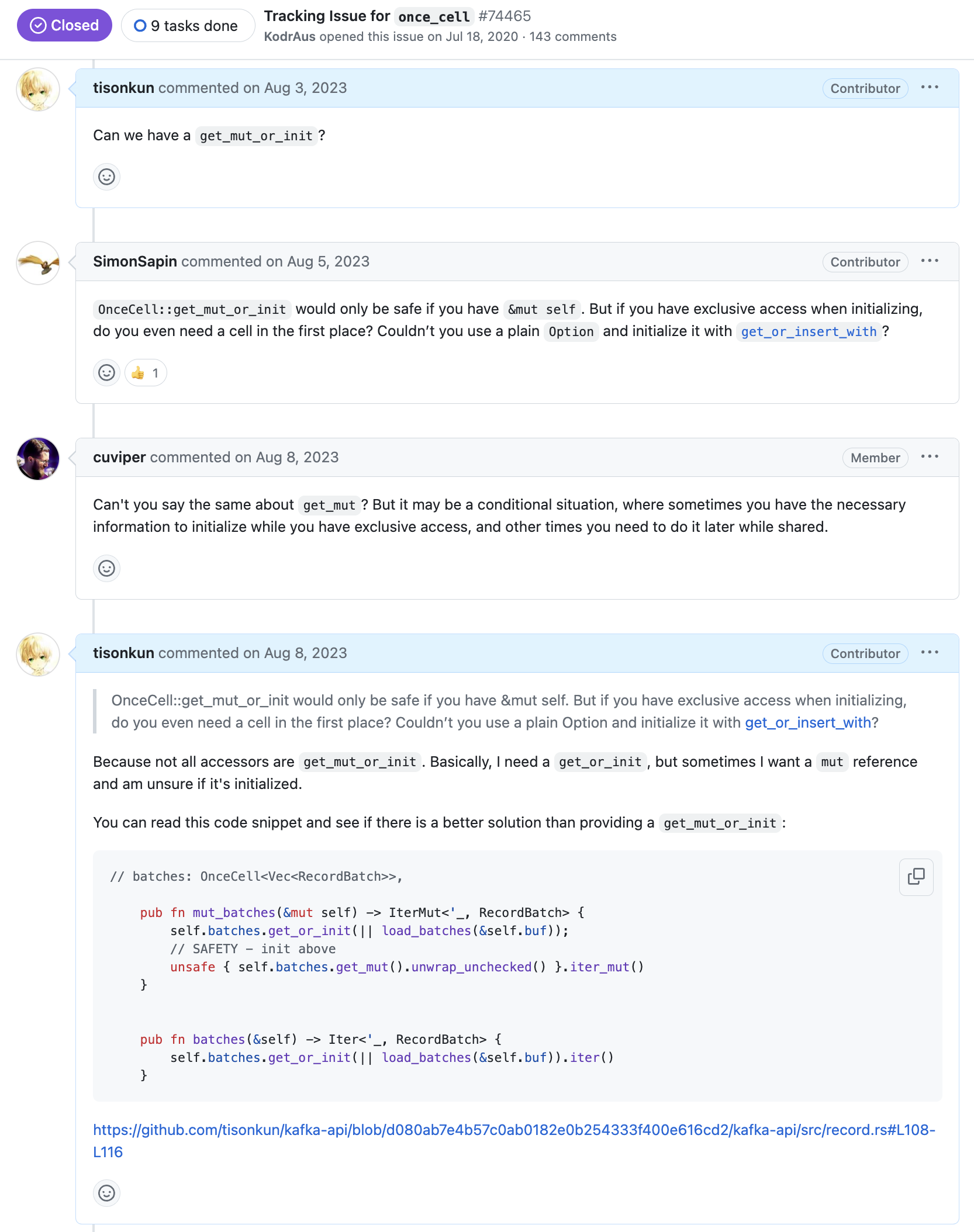
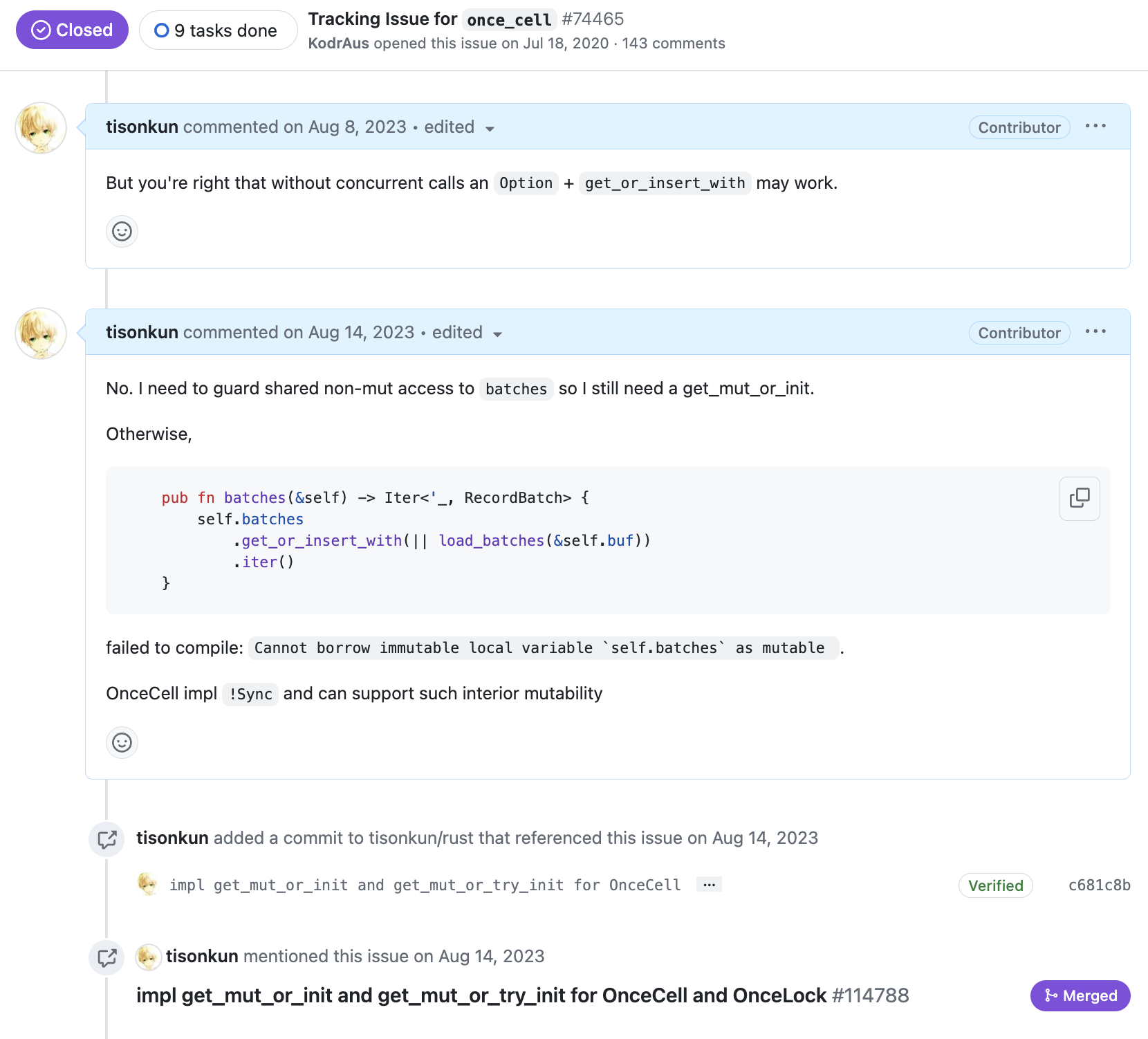
进一步地,之所以会提出这个问题,是我当时在实现 Apache Kafka API 当中 RecordBatch 接口,其中涉及到一个解码后缓存结果的优化。因为 Rust 对所有权和可变性的各种检查和契约,如果想用 OnceCell 来实现仅解码(初始化)一次的效果,又想要在特定上下文里取得一个可变引用,那就需要一个 get_mut_or_init 语义的接口。
实际上,这个接口的实现跟现有的 get_or_init 逻辑几乎一致,除了在接收者参数和结果都会加上 &mut 修饰符以外,没有区别。所以我倾向于认为是一开始加的时候没有具体的需求,就没立刻加上,而不是设计上有什么特殊的考量。
于是,开始讨论后的下一周,我就提交了实现功能的代码补丁。很快有一位志愿者告诉我应该到 rust-lang/libs-team 仓库走 ACP 的流程,我读了一下文档,尝试跟提出这个要求的志愿者 confirm 一下具体的动作。不过马上就是两个多月的毫无响应,我也就把这件事情暂时搁置了。
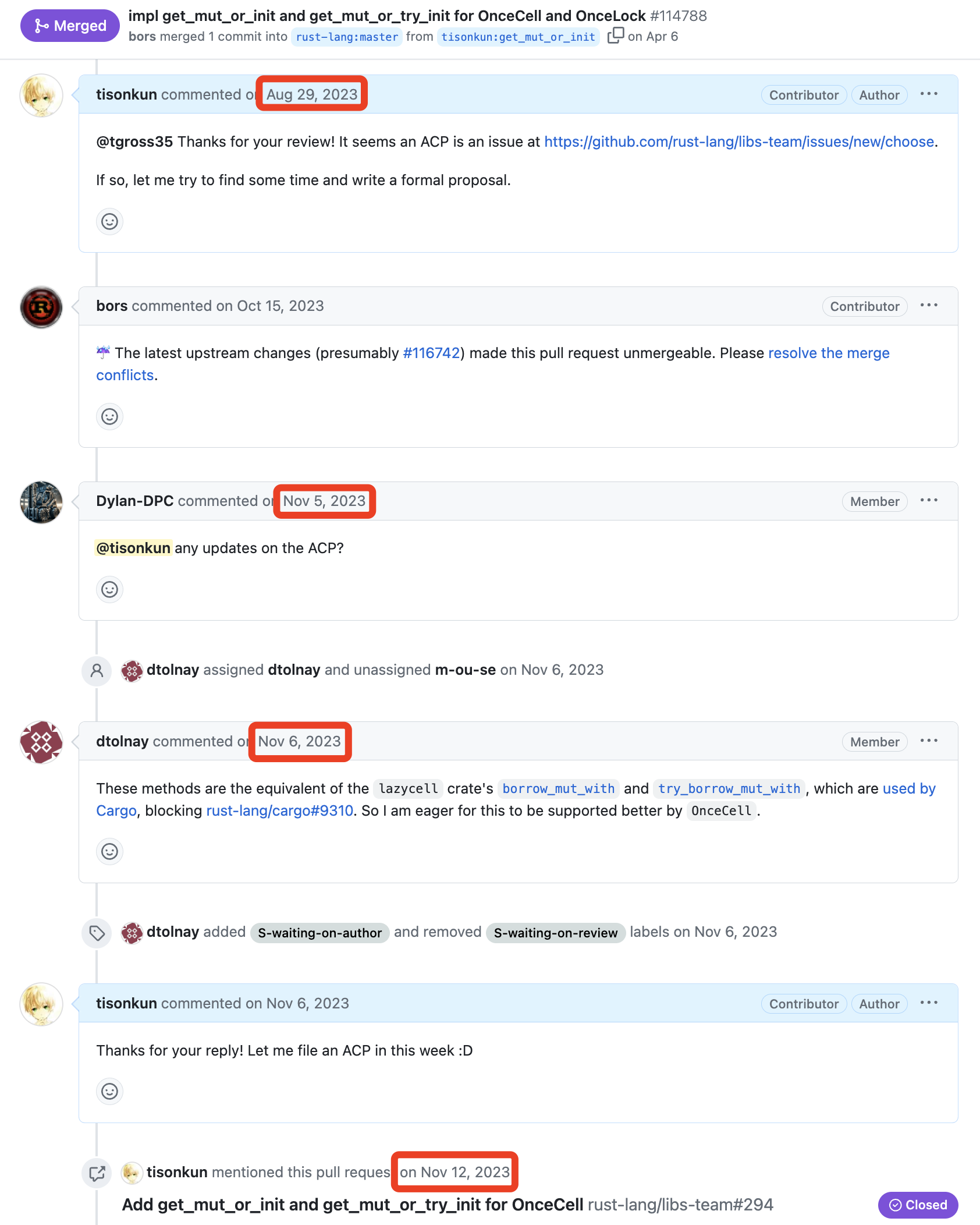
11 月,两位 Rust 语言的团队成员过问这个补丁。尤其是我看到 Rust 社群著名的大魔法师 @dtolnay 表示这个补丁确实有用,应该合进去以后,我感觉信心倍增,当周就把 ACP 的流程走起来了。
随后就是又两个月的杳无音讯……
今年 1 月,@dtolnay 的指令流水线恰巧把这个 PR 调度上来,给我留了一个 Request Changes 让我修一下编译。发现我凭直觉写出来的合理代码遇到了另一个 Rust 编译器的 BUG 导致编译不过:
解决以后,社群志愿者 @tgross35 指导我给新的功能添加 unstable feature 的属性注解,也就是:
1 |
另一位社群志愿者 @programmerjake 帮我指出几个文档注释的问题,为标准库添加新接口不得不写好接口文档,摆烂不了。
在此过程中,我给 OnceLock 也同样加了 get_mut_or_init 和 get_mut_or_try_init 接口,因为它和 OnceCell 本来就是同期进来的,接口设计也一模一样。我想那就一起加上这个接口,免得 OnceLock 后面有同样的需要还要另走一次 ACP 流程。
这悄然间又是两个月过去了……
终于,在 @programmerjake Review 完之后一周,@dtolnay 出现并 Appove 后合并了代码。
第一次 Rust 主仓库参与贡献至此告一段落,唯一剩下的就是等 libs-team 主观认为合适之后启动功能 stabilize 的流程。
上个月,有人发现之前写的文档注释还是有错误,于是提交 PR 修复。这就是某种开源协同让代码质量向完美收敛的过程。
为什么会想到给 Path 加接口?
这个动机要追溯到我用 Rust 重写 License Header 检测工具 HawkEye 的时候了。
Rust 重写 HawkEye 的动机,则是为了支持调用 Git 库跟 gitignore 的机制做集成。虽然原先 Java 的实现可以有 JGit 来做,但是 JGit 的接口很脏,而且加上 JGit 以后就不能 Native Image 了导致分发产物体积显著变大。虽然都不是什么大事,但是工具类软件本来就是强调细节处的开发者体验,正好我逐渐掌握了 Rust 编码的技巧,就拿上来练练手。
今年 3 月重写 HawkEye 的时候,我发现了 Rust 标准库里 Path 结构缺一个接口:
1 | let mut extension = doc.filepath.extension().unwrap_or_default().to_os_string(); |
我在写上面这段代码的时候,目的是给文件名加一个 .formatted 后缀。但是,Path 的 with_extension 接口是直接替换掉扩展名,也就是说,原本我想要的是 file.rs 变成 file.rs.formatted 的效果,如果用 with_extension 接口,就会变成 file.formatted 这样不符合预期的结果。
最终,只能用上面这样的写法手动绕过一下。显然代码变得啰嗦,而且这段代码是依赖 extension 的底层实现细节,某种程度上说是 brittle 的。
遇到这个问题的时候,我就想给标准库直接提一个新的 PR 了。不过当时 OnceCell 和 OnceLock 的 PR 还没合并,我拿不准 Rust 社群的调性,也不想开两个 PR 都长期 pending 下去。
好在上一个 PR 在几周后顺利合并了,我于是同时创建了 ACP 和 PR 以供社群其他成员评审。因为改动面很小,比起口述如何实现,不如直接在 ACP 里链接到 PR 讲起来清楚。
这次,提案很快得到 Rust 团队成员,也是我的前同事 @kennytm 的回应。不到两周,我就按照上次的动作把 PR 推到了一个可以合并的状态。
然后又是两个月的杳无音讯……
最后,我根据其他社群成员的指导,跑到 Rust 社群的 Zulip 平台上,在 libs-team 的频道里几次三番的问:“这个 ACP 啥时候上日程啊?”
终于,在今年 7 月初,libs-team 在会议上 appove 了 ACP 的提议,并在一周内再次由 @dtolnay 完成合并。
开发者的需求是开源贡献的源动力
可以看到,上面两个贡献的源动力,其实都是我在开发自己的软件的时候,遇到的 Rust 标准库缺失的接口,为了填补易用接口的缺失,我完成了代码开发,并了解社群流程以最终合并和发布。在最新的 Rust Nightly 版本上,你应该已经能够使用上这两个我开发的接口了。
在开源共同体当中,一个开发者应该能够发现所有的代码都是可以更改的。这是软件自由和开源定义都保证的事情,即开发者应该能够自由的更改代码,并且自由地使用自己修改后的版本。
那么,开发者在什么时候会需要修改代码呢?其实就是上面这样,自己的需求被 block 住的时候。小到 Rust 标准库里接口的缺失,大到我之前在 Apache Flink 社群里参与的三家公司合作实现 Application Mode 部署,甚至完全重新启动一个开源项目,说到底核心的源动力还是开发者真的对这样的软件有需要。
因此,开发者的需求是开源贡献的源动力。一旦一个开源软件不再产生新需求,那么它就会自然进入仅维护状态;而一旦一个开源软件不再能够满足开发者实际的需求,甚至开发者连直接修改代码的意愿也没有,那么它的生命也就到此为止了。
Logforth: 从需求中来的 Rust 日志功能实现
由此,我想介绍一个最近在开发 Rust 应用的时候,由自己需求出发所开发的基础软件库:
Rust 生态的日志组件,由定义 Logging 接口的 log 库和实现 Logging 接口的各个实现库组成。其中,log 库可以类比 Java 日志生态里的 SLF4J 库,而日志实现则是 Logback 或 Apache Log4j 这样的库。实际上,Logforth 的名字就来自于对 Logback 的致敬。
编写 Logforth 的动机,是我在选择 Rust log 实现的时候,现有所有实现都不满足我的灵活定制需求。生态当中实际定位在完整 log 实现的库,只有 fern 和 log4rs 这两个。其中,fern 已经一年多没有新的发布了,一些显而易见的问题挂在那里,内部设计也有些叠床架屋。而 log4rs 则是对 Log4j 的直接翻译,也有许多非常诡异的接口设计(底层问题是 Java 的生态和设计模式到 Rust 不能直接照搬)。
于是,我花了大概两个小时的时间,梳理出 Rust 和 Java 日志生态里日志实现库的主要抽象:
- Appender 定义日志写出到目标端的逻辑;
- Filter 定义日志是否要打印的逻辑;
- Layout 定义日志文本化的格式。
然后花了一天的时间,把 log4rs 的主要 Appender 即标准输出和(滚动)文件输出给实现了,同时完成了基本的基于日志级别的 Filter 和纯文本以及 JSON 格式的 Layout 实现,就此发布的 Logforth 库。
经过两周的完善,目前 Logforth 库已经具备了全部日志实现所需的基本能力,且可以自由扩展。接口都非常干净,文档也都补齐了。除我以外,一开始一起讨论需求的 @andylokandy 也极大地帮助了 API 的设计跟多种常用 Appender 的实现和优化。应该说,目前的 Logforth 已经是超越 fern 和 log4rs 的库了。
而回到本文的主题,之所以我能在一天时间内就写出第一个版本,我跟 @andylokandy 能目标明确、充满动力地实现 Logforth 的功能,就是因为看到了自己和整个 Rust 生态的需求,并且我们清楚应该怎么实现一个足够好的日志库。
Rust 生态的诸多潜在机会
最后,为坚持到这里的读者分享几个我看到的 Rust 生态潜在的机会。
总的来说,目前整个 Rust 生态接近 Java 1.5 到 1.7 时期的生态,即语言已经流行开来,核心语言特性和标准库有一些能用的东西,整体的调性也已经确定。但是,距离 Java 1.8 这样一个全面 API 革新的版本还有明显的距离,核心语言特性的易用性有很大的提升空间,标准库的 API 能用但算不上好用,开源生态里开始出现一些看起来不错的基础库,但是还远远没有达到 battle-tested 的状态。
第一个巨大的缺失点就是 Async Rust 的实用工具。我找一个 CountdownLatch 的实现,找了半天才发现去年底发布的 latches 库符合我的期待。要是去年我有这个需求,就真没人能搞定了。后来我要找一个 Async 版 WaitGroup 的实现,找来找去没有一个合适的,只能自己 fork waitgroup-rs 改改来用。
Crossbeam 是个很不错的高质量库,可惜它提供的是同步版本的并发原语,不能在 Async Rust 里使用。上面 latches 和 waitgroup-rs 单看实现得还可以。但是这种单文件库,真的很难长期维护,而且像 latches 这样一个结构硬整出各种 feature flags 的做法,其实是反模式的,没必要。
所以一个 async-crossbeam 可能是目前我最想看到的社群库,或许它可以是 futures-util 的扩展和优化。这些东西不进标准库或者事实标准库,各家整一个,真的有 C++ 人手一个 HashMap 实现的味道了。
第二个缺失点,顺着说下来就是 Async Runtime 的实现。Tokio 虽然够用,但是它出现的时间真的太早了,很多接口设计没有跟 Async Rust 同步走,带来了很多问题。前段时间 Rust Async Working Group 试图跟 Tokio 协商怎么设计标准库的 Async Runtime API 最终无疾而终,也是 Tokio 设计顽疾和社群摆烂的一个佐证。
async-std 基本已经似了,glommio 的作者跑路了,其他 xxx-io 的实现也有种说不出的违和感。这个真没办法,只能希望天降猛男搞一个类似 Java ExecutorService 这样的体系了。而且最好还要对 Send + Sync + 'static trait bound 做一些参数化,不用全部都强行要求……
IO 和 Schedule 虽然有关系,但还是不完全一样的概念。总的来说 Rust 生态里暂时没有出现跟 Netty 一样 battle-tested 的网络库,也没有能赶上 ExecutorService 生态的 battle-tested 的异步调度库。不过好的调度原语库还是有一些的,比如 crossbeam-deque 和 soml-rs 里的相关库,等待一个能合并起来做高质量 Runtime 的大佬!
第三个缺失点还是跟 Tokio 有关。应该说 Tokio 确实做得早而且够用,但是很多设计到今天看就不是很合适了,然而社群里用得还是很重,就变得更不好了。比如上面的 log 库,Tokio 生态里搞了个叫 Tracing 的跟官方 log 库不兼容的接口和实现,也是一大堆槽点。
这里想说的是 bytes 库。很多 Rust 软件闭眼睛就用 bytes 处理字节数组,这其实有很大的性能风险。例如,基于 bytes 搞的 PROST 就有一些莫名其妙的的多余拷贝,可参考《Rust 解码 Protobuf 数据比 Go 慢五倍?》。值得一提的是,PROST 也是 Tokio 生态的东西。
Apache OpenDAL 内部实现了一个 Buffer 抽象,用来支持不连续的字节缓冲区。这个其实也是 Netty 的 ByteBuf 天生支持的能力。如果现在 Rust 有一个 Netty 质量的网络库,有一个 ExecutorService 的接口跟一些基本可用而不像 tokio 一样全家桶的实现,再把文件系统操作搞好点,我想整个 Rust 生态的生产力还能再上一个台阶。
Rust 的 Async FileSystem API 实现现在没有一个能真正 Async 的,这个其实 Java 也半斤八两。不过 Rust 的
io::copy不能充分利用 sendfile syscall 这个,就被 Java 完爆了。这点是 Apache Kafka 实现网络零拷贝的重要工程支撑。
最后一个,给国人项目做个宣传。Rust 的 Web 库也是一言难尽,同样是 Tokio 生态的 Axum 设计让人瞠目结舌,整个 Rust 生态对 Axum 的依赖和分发导致了一系列痛苦的下游升级体验,可参考 GreptimeDB 升级 Axum 0.7 的经历,至今仍然未能完成。
国内开发者油条哥搞的 Poem 是更符合 Web 开发习惯的一个框架,用起来非常舒服,也没有奇怪的类型挑战要突破。Poem 的最新版本号是 3.0.4 而不是像 Axum 的 0.x 系列,这非常好。
不过,Poem 的接口文档、回归测试跟一些细节的易用性问题,还需要更多开发者使用慢慢磨出问题跟修复。希望 Poem 能成为一个类似 Spring 的坚固 Web 框架,这样我写 Rust 应用的时候,也能省点心……
举个例子,我的一个 Poem 应用里有 query handle panic 的情况,就踩到了 Poem 一个并发对齐的设计没有处理 panic 的缺陷。当然,我顺手就给修了,所以新版本里应该没这个问题。
至于文档不全的例子,主要是错误处理的部分,应该需要更多最佳实践。
无论如何,目前 Rust 生态整体的生产力和生产热情,还是比 Java 要高出太多。长期我是看好 Rust 的发展的,短期我只能安慰自己 Netty 是一个在 Java 1.6 才出现,1.8 才开始逐渐为人熟知使用,5.x 胎死腹中,发展时间超过 15 年的项目,生态要发展并不容易了。