Fastrace: 高效易用的 Rust 分布式追踪方案
随着应用程序从单体走向分布式微服务架构,追踪(Trace)请求在各个模块间的流转变得越来越重要。然而,现有应用系统还没充分认识到分布式追踪的价值和必要性。这很大程度上是因为生态当中缺乏一个可靠、高效且易用的分布式追踪方案。
Rust 生态尤其如此。作为一个新兴的语言生态,可供 Rust 开发者选择的追踪框架并不多。目前常用的 tokio-rs/tracing 库存在明显的生态割裂、配置负载和运行低效的问题。在研发 ScopeDB 的过程中,我们深刻认识到分布式追踪对系统可观测性及问题排查的重要性。为了解决 Tracing 存在的问题,我们基于现有开源软件分叉开发维护了 Fastrace 框架。
Fastrace 经过生产环境的高压检验,可为用户提供一致且简单的 API 体验,并能与现有的 Rust 生态无缝集成,尤其是提供了高效丝滑的 OpenTelemetry 集成体验。以下是使用 Fastrace 追踪请求的简单示例:
1 |
|
ScopeDB 线上环境中一个分布式追踪的可视化实例:

本文先介绍分布式追踪及其价值,然后讨论 Fastrace 如何解决此前 Rust Tracing 方案中没能解决好的问题,并给出一个完整的日志追踪方案。最后,分享 Fastrace 开源背后的故事。
分布式追踪
如同前面的示例图所示,所谓追踪,就是记录一个请求在系统当中如何流转的一系列事件。每个事件记录有对应的名称,起止时间(Span),以及调用间的父子关系。
在单体应用当中,请求流经一个同一进程的不同模块,记录请求的流转可以在内存当中完成,并在最后统一上报。然而,在分布式微服务架构下,一个用户请求在完成之前可能会流经十几乃至数十个服务进程,如何串联起不同进程记录的事件信息就成为一个挑战。单纯依赖传统的日志记录方法无法关联起不同进程的日志事件。
考虑一个典型的请求流程:
1 | User → API Gateway → Auth Service → User Service → Database |
如果请求抛出异常,或者应用出现性能瓶颈,如何定位根本原因?单个服务的日志只会包含整个请求追踪的片段信息,缺少请求在整个系统中如何流动的关键上下文。
分布式追踪就是解决这一问题的关键技术。它通过实现跨服务边界建立起请求流转的关联视图,达成以下目标:
- 发现跨服务调用的性能瓶颈;
- 调试组件之间的复杂交互;
- 理解服务模块的依赖关系;
- 分析异常值的分布和原因;
- 将日志、指标与请求上下文相关联。
Why Tracing Fails
我们先看看 tokio-rs/tracing 库的典型用例:
1 | async fn business(user: &User, password: &str) -> Result<(), Error> { |
根据我们使用 Tracing 的经验,用户主要会遇到以下三个问题。
生态割裂
很明显的一点就是,一旦用上 Tracing 库,你就要使用 tracing::info! 等一系列专用的宏指令,而不是 Rust 官方的 log 库对应的宏指令:
1 | // Using log crate |
虽然 Tracing 生态提供了一系列适配器在 log 和 tracing 之间做桥接,但是最终用户必须选择其一作为实施方案。
对于库作者来说,必须决定自己的库在提供调试信息时,使用 tracing::info! 还是 log::info! 来打日志。大部分 Rust 库选择官方的 log 库,但这样就会缺少 tracing 对应的功能。即使有适配器桥接,适配过程也会损失一些信息或能力。而如果使用 Tracing 来记录日志事件,则需要额外提供可选或必选地启用 log 功能标志来保证所有用户都能正确接收到日志事件。这给库作者带来了额外的配置复杂性。
对于应用开发者来说,在使用 Tracing 时也要对应的启用适配器。这将带来双向兼容的配置负担:
1 | # Library's Cargo.toml |
后面我们会看到,Fastrace 和 log 库提供的宏集成良好,从设计上根本不需要一套独立的宏指令。
性能瓶颈
对于库作者来说,追踪能力显然应当是可选的,因为库代码可能在频繁的循环或性能关键路径中被调用。Tracing 的插桩开销可能非常大,这造成了一个困境:
- 库代码要么选择永远插桩,这会导致所有用户不可避免的承担对应的开销;
- 要么选择永远不插桩,那也就完全没有事件记录,更谈不上构建追踪;
- 要么,创建一个新的功能标志,可选的启用插桩功能。
第三种方式是可行的,但是并不合理。以下是一个典型的折衷实现:
1 |
|
自定义功能标志使得配置的复杂度直线上升。不同的库作者可能会选择不同的功能标志名称,于是我们回到了 CMake 里 ENABLE_TEST / ENABLE_TESTING / ENABLED_TEST / TEST_ENABLED 的标志地狱。
这种复杂性经常导致库作者放弃对一切可能在热路径中被调用的函数进行追踪插桩。于是在真的需要排查问题时,下游用户只能 Fork 出来手动插桩,整体增加了生态使用的成本。
失去关联
如果说前面两个还算能捏着鼻子接受,那么最后一个问题就是防不胜防的无情刺客。
前面介绍到,分布式追踪最重要的就是跨服务边界传播上下文,但是 Tracing 库并没有提供开箱即用的上下文传播集成,而是让开发者自求多福。例如,下面的 Tonic 官方示例演示了如何追踪 gRPC 服务:
1 | Server::builder() |
很可惜,这个示例是有问题的。因为它只创建了一个基础的 Span 而没有从传入请求中提取跟踪上下文。
这会导致分布式追踪完全崩溃。例如,对于一个逻辑上完整的请求流程:
1 | Trace #1: Frontend → API Gateway → User Service → Database → Response |
上面的配置可能会看到两个不相关的链条:
1 | Trace #1: Frontend → API Gateway |
或者更糟糕一点,真正的线上环境当中,请求是并发到达的,于是你将看到:
1 | Trace #1: Frontend → API Gateway |
某种角度上说,只要付出一定的额外努力把 tracing context 串起来,还是能搞出一条完整的追踪链的。但是这就要求每个应用开发者针对他使用的所有库都要做审计和可能的适配,这就是暗处防不胜防的无情刺客,用上 Tracing 这辈子有了。
最后,Tracing 的维护状况也不容乐观。0.2 版本数年难产,且在有上述明显问题的情况下,tokio-rs/tracing 最近两个版本分别在 2023 年和 2024 年发布。应当说,作为 Rust 生态重要的依赖库,Tracing 既不完善,也没有积极维护和迭代。这也是我一直吐槽 tokio 系生态的一个点:传播错误的实践。
Fastrace 的设计理念
Fastrace 在设计迭代的时候充分考虑了库作者和应用作者的需求,把一个分布式追踪库本来就应该做的事情在库范围里都做完了。
简单易用
所有接口和配置都按最小原则正交设计,为常见用例提供最简单的上手体验,同时在需要时仍提供可扩展性。
绝大部分情况下,只需要用 #[fastrace::trace] 标注希望追踪的函数,启用所需的生态集成,并在入口设置好 Span 的 Reporter 即可。在 Span 需要调优的情况下,可以自行定义 Span 的名称、父子关系及采样逻辑等属性。
零成本抽象
Fastrace 在上游就定义了 enable 标志。如果不设置这个标志,也就是 disabled 的情况下,插桩注解在编译时会被完全跳过,因此用户可以自由地选择 opt-out 不想要的开销。
因此,库作者可以总是使用 #[fastrace::trace] 标注希望追踪的函数,而无需担心引入固定的开销:
1 | // No cost if application does not turn on the 'enable' feature |
这里的重点在于,库作者总是不需要启用 enable 功能标志:
1 | [dependencies] |
应用开发者可以根据情况选择是否启用追踪功能。如果不启用 enable 标志,那么:
- 所有插桩代码都不会生成,被标注的函数就是按原样编译。
- 于是,运行时也就没有相关的开销。
- 因此,性能关键路径不会增加额外的延迟。
如果启用了 enable 标志,那么:
- 插桩代码自动生成,自动创建 Span 记录请求流转产生的事件。
- 产生的 Span 自动收集到 Reporter 中并上报。
- 应用可以看到库函数调用的整个链路信息。
如果应用开发者要详细调节具体库调用的追踪粒度,可以通过设置 SpanContext 的 sampled 属性减少运行时开销。
跟其他 Rust 生态中的追踪方案相比,这是一个明显的优势。其他方案要么总是产生开销,要么需要库来实现复杂的功能标志系统。
生态兼容
Fastrace 专注在完成分布式追踪需要的功能。因此,我们没有重新发明一套日志记录宏,而是通过正交、可组合的设计,保证它能够与 Rust 官方的 log 库无缝集成。同时,Fastrace 第一方提供了与 Rust 生态中常用库的集成,用户无需额外开发就能和 reqwest / axum / poem 等方案集成,保证从头到尾串联起来请求追踪。
1 | // For HTTP clients with reqwest |
极致性能
Fastrace 全面优化了追踪采集的开销,保证在高性能应用当中仍然能够允许用户尽可能多的采集可观测信息。下面的性能测试数据显示 Fastrace 对业务延迟的影响是其他方案的 1/10 甚至 1/100 不等。
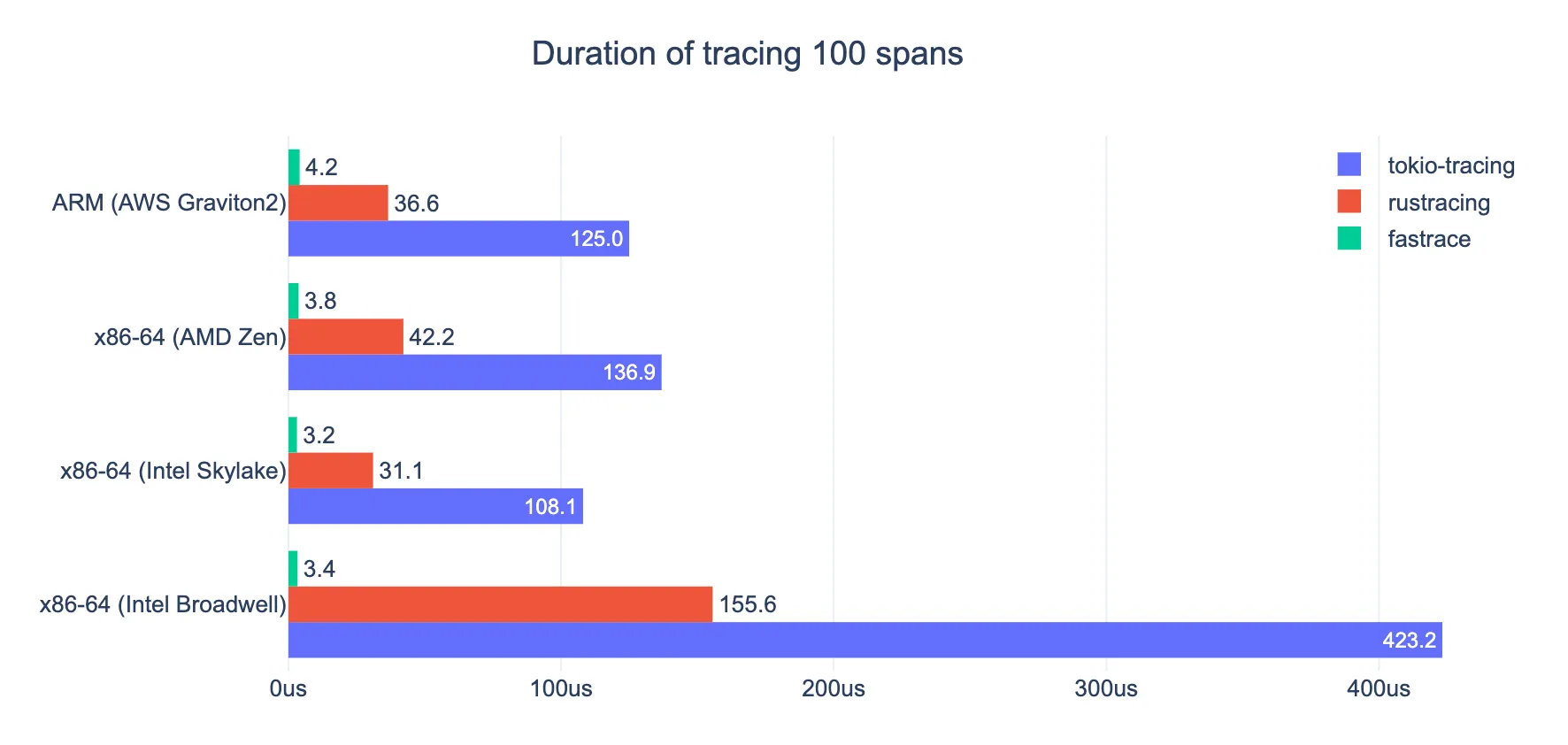
构建完整的日志追踪方案
Fastrace 专注于实现分布式追踪的核心功能。为了构建一个完整的日志追踪方案,我们需要将 Fastrace 与其他 Rust 库结合使用。
在 ScopeDB 的生产实践中,我们选择了以下组合:
- log Rust 官方的日志门面(Facade)库,提供打日志的接口。
- logforth 一个多功能且可扩展的日志实现,可以对接 log 库的接口。这也是 ScopeDB 开发过程中衍生的一个开源库。
- fastrace 即我们在这里介绍的库。
这个方案使得应用只需要简单的用 #[fastrace::trace] 标注函数或其他方式划定 Span 的范围,并使用 log::info! 等宏打印日志,就可以把请求追踪的链路和上下文完整的记录下来:
1 | log::info!("Processing started"); |
下面是一个完整的配置和端到端请求的例子:
1 |
|
Fastrace 的开源故事
本文一开始提到,Fastrace 是我们在开发 ScopeDB 的过程中,为了解决 Tracing 存在的问题,基于现有开源软件分叉开发维护的。既然是分叉,那就肯定有一个上游。如同 Fastrace README 当中写到,Fastrace 是从 Minitrace 分叉出来的,而 Minitrace 是 TiKV 组织下开发的追踪库,可惜没有被用在生产环境当中。
相关的讨论可以看这个帖子:
某种程度上说,TiKV 是 Rust 生态早期的一个创新中心。它能吸引到几位 Rust 核心团队的开发者加入就是一个例证。在 Rust 生态还极其不完善的时候,它提供过一系列开源方案:
- rust-rocksdb
- pprof-rs
- rust-prometheus
- fail-rs
- raft-engine
- jemallocator
- grpc-rs
- raft-rs
- yatp
- protobuf-build
- agatedb
- minstant
- crc64fast
- match-template
- mur3
- slog-global
这其中,有至今仍被使用的软件库,比如 ScopeDB 就用到了 jemallocator 和 match-template 这两个。此外,raft-rs 和 crc64fast 也有不少受众。
不过,这其中也有很多方案没有形成社群,没有跟其他同类项目沟通,逐渐式微或被替代。例如 rust-rocksdb 永远和上游分叉了,rust-prometheus 被官方推出的 client-rust 替代,grpc-rs 基本被 tonic 替代,甚至在 Google 的 gRPC 团队想要投入做一个技术方向上跟 grpc-rs 一样是 C++ 核心 Wrapper 的方案时,也是找的 tonic 的人,而非 grpc-rs 的人。
agatedb 没有投入过生产环境;slog-global 随着上游式微逐渐进入只维护模式。minstant 和 minitrace 也没有投入过生产环境,其作者后来将之带到更广阔的使用场景,因为实在和 TiKV 没什么关系,经过讨论,由于 CNCF 的项目不好把知识产权再转移出去,只能重命名后 Fork 出来开发,也就是现在的 Fastrace 和 Fastant 项目。
关于 Fastrace 的名字来源,还有一段有趣的故事。Hacker 玩家肯定知道,这个名字取得是 Fast Trace 的意味,然后颇具 Hacker 趣味地把相同的 T 合并,于是拼成了 fastrace 这个名字。不过 Hacker 趣味的名字一般在传播尤其是口语传播里都有问题,所以我不只一次看到用户直接就拼成 fasttrace 来讨论问题。
有趣的故事是,一开始 Fastrace 从 Minitrace 分叉出来开发的时候,顺其自然是放在一个叫 fastracelabs 的 GitHub 组织下的。这个时候,Fastrace 的“联合创始人”漩涡发现,GitHub 上叫 fast 的组织虽然有人注册了,但是并没有实际使用。巧合地是,fast 组织的所有者的联系方式并不难获取,而且恰好是个中国人。于是漩涡致信看看能不能请对方帮个忙,没想到 fast 组织原所有者直接将 org 转交给我们使用,实在是太好了 ><
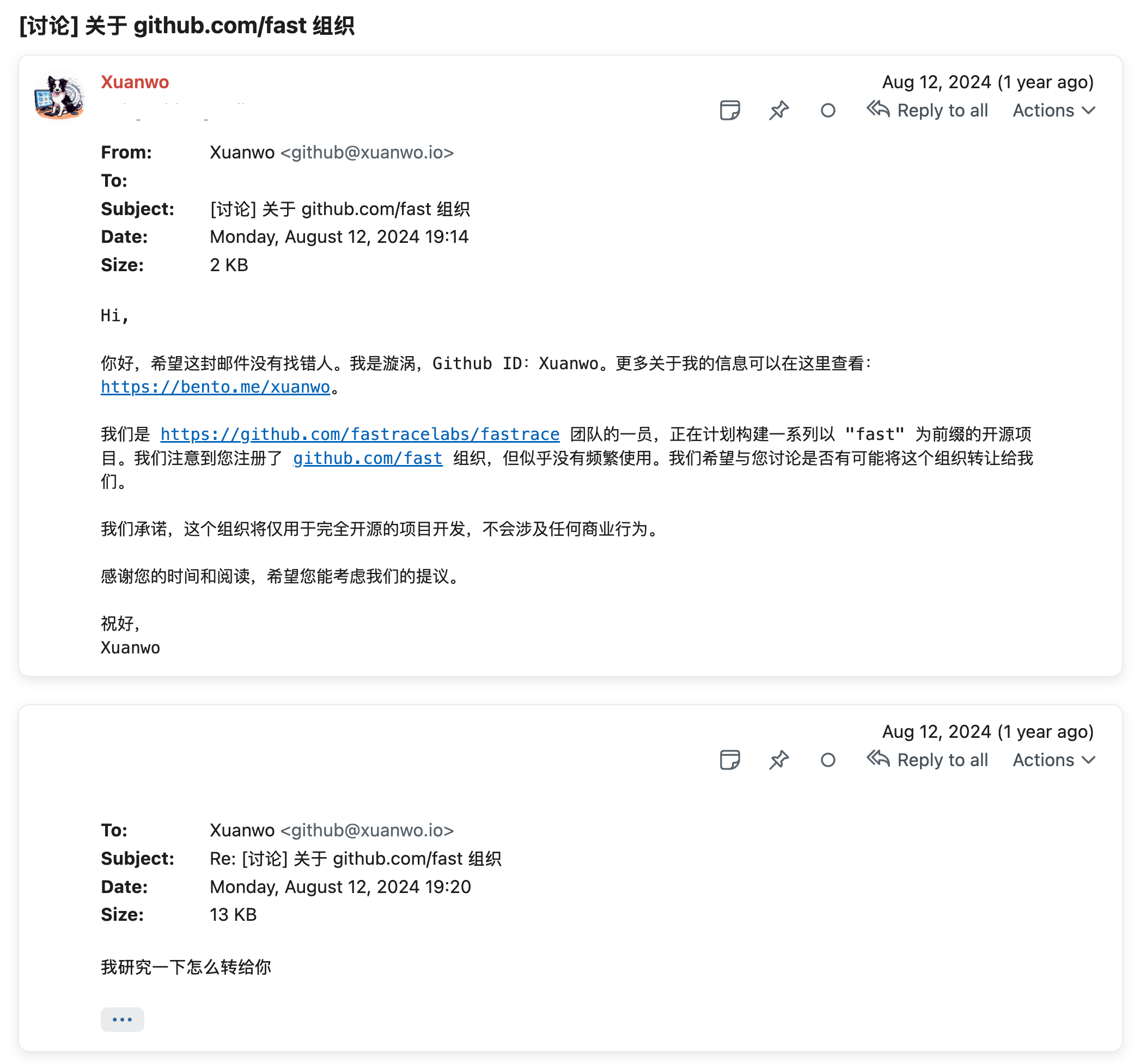
后来,因为这个组织名字确实很好,我们又在这个名下开发了 fasyslog 和 fastpoll 等项目,当然也有一些项目没有 fast 前缀的迷因,比如 logforth 和 stacksafe 等。
可以看到,fast org 正在成为 Rust 生态又一个创新中心。我去年有过一个判断,就是目前的 Rust 生态大约可以对应到 Java 1.5 到 1.7 之间。一些标志性的成果,比如 Java 的 Future 在 1.5 出炉,但是直到 1.8 CompletableFuture 之前,其实类似 Netty 和 Apache Kafka 这样的项目,都在包自己的 Future 接口和实现,而 Java 21 以后又再推出了 VirtualThread 新方案。作为对比,Async Rust 现在从标准库接口,生态的成熟度和易用性,都远远达不到工匠级别的可靠(当然该说不说,生产环境用用,大部分时候也还说得过去,Java 1.2 都能用,是吧)。而现在 Java 开发者们熟悉的 Spring 框架,Netty 网络库,以及 Apache Hadoop 为代表的大数据生态的早期项目,都是在这个时间段发展起来的(甚至你能从 Apache ZooKeeper 的网络处理和异步处理中看到横跨 15 年以上的演化痕迹)。所以,应当说,现在的 Rust 生态,正是大有可为的时候。
例如,Rust 生态的加密库,虽然大家目前都闭着眼睛相信了 Rust Crypto 组织,但是大哥的 Break Changes 和开发周期也不是很能恭维。当然,目前没有比它更好的了,所以对于 Rust Crypto 组织我更想号召社群开发者参与支持加速发布。例如,Rust 的异步生态,虽然有 tokio 这个默认或者说唯一的选择,但是不管是 Runtime 对于特定应用负载处理不好调优,还是没有把 Async IO 和 Async Scheduler 往标准库推,抑或是 Primitives 实现的历史债务,都有很多问题待解决。我在后续的文章讲到 ScopeDB 开源的异步工具库 Mea 的时候会详细介绍这里面的想法。
如果你有兴趣在这个关键的时候加入到 Rust 生态大开发当中,欢迎联系我,或者从 fast org 下的任何项目开始参与。我相信我们现在做的工作,会成为未来的 Rust 大厦坚实的基础。
版权说明
本文关于 Fastrace 技术部分的介绍,大多参考自 Fastrace 主要作者 @andylokandy 发布在 fast.github.io 的英文博文。相关内容引用已取得授权。