Apache Pulsar 的社群指标
去年十一月,我成为了 Apache Pulsar 社群 Committers 的一员。
成为 Committer 之前和之后,我都积极参与了代码仓库上 Issue 和 Pull Request (PR) 的处理回应和评审。去年十二月期间,我把未解决的 Issue 和 PR 数量分别从接近 2000 个和 400 个,在动态增长的情况下缩小到了小于 1000 个和接近 200 个。
关于如何高效地、分门别类地处理社群积压的议题和补丁,我可能会用另一篇文章来讨论。本文想讲的是在这个过程里我产生的另一个想法,那就是如何分析在这类过程中产生的活动,从而判断社群的健康情况呢?
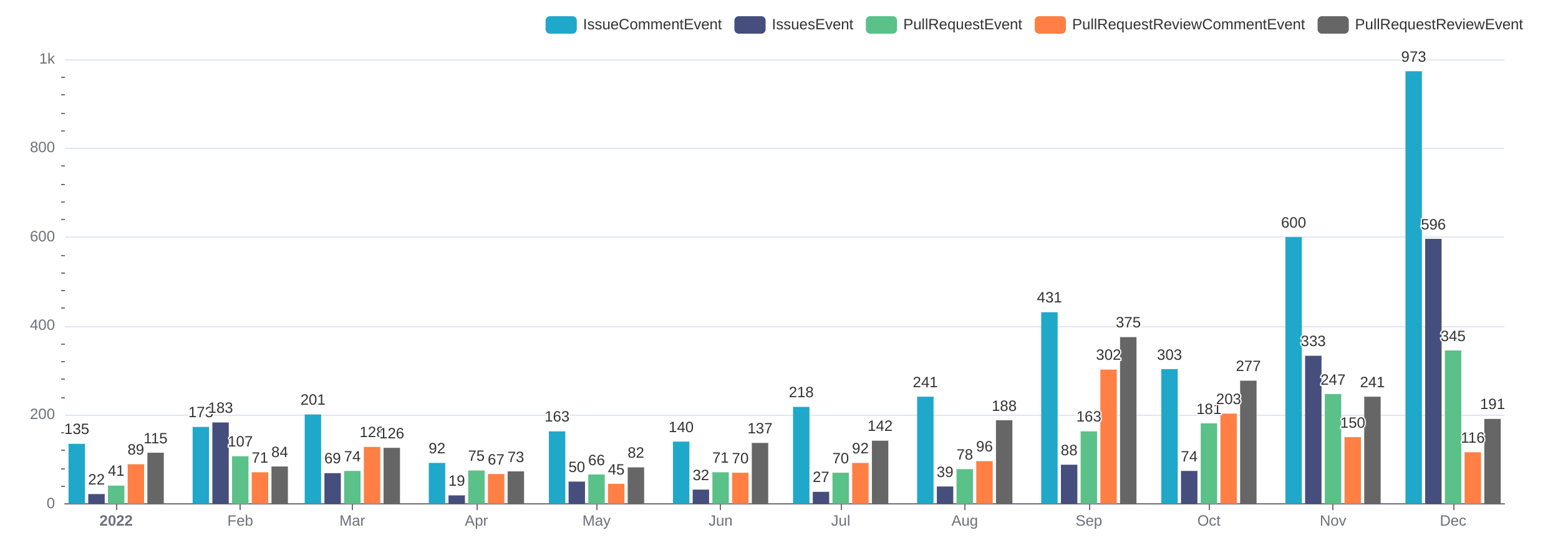
数据源与展示
要想做数据分析,首先应该确定使用什么数据源。不同数据源的数据质量和数据口径有很大的差距,可能导致同一个逻辑概念最终算出来的结果之间大相径庭。
我们的目标是分析社群成员的在 GitHub 平台上的活动指标和趋势,而 GitHub 本身提供了 Event 接口获取平台上的所有公开活动。
不过,这个接口返回的数据只有最近九十天的数据,要想获取完整的数据,就需要依靠一个从近十年前已经开始爬取 GitHub Events 数据并提供开放下载的项目 GH Archive 了。关于如何从这个数据集构建一个自有的数据源,可以参考《基于 ClickHouse 的 GitHub 事件数据库》这篇文章。
GH Archive 提供的是 GitHub 全平台所有活动的数据。由于 GitHub 日益活跃,这个数据集的总体大小在几个 TB 的量级。虽然对于一个具体项目社群比如 Pulsar 来说,筛选出与己相关的仓库的活动最终大约只有 MB 量级的数据,但是使用 GH Archive 的数据始终要过一遍全量的活动数据。
另一种方案是把 GH Archive 的工作也集成到数据源制作的工具集里,直接从 GitHub 的 Event 接口里仅拉取相关仓库的活动。这样做可行的原因是往往最近的数据才是最有价值的,一个仓库五年前是什么活跃水平,很大程度上只是一个图一乐的数字。不过,要想这么做,数据源生成的流水线也不简单,需要维护一个定期任务的调度,以及数据去重和补偿的逻辑。
最终,我选择了国内 X-Lab 开放实验室维护的、基于 GH Archive 数据的、存储在 ClickHouse 当中并提供相同查询接口的 GitHub Event 数据集。该数据集的数据模式定义是公开的,相比 ClickHouse.com 提供的 github_events 数据集,X-Lab 的数据集包含了实验室在开源数据指标工作中发现的有效提高数据可用性的字段,包括 repo_id 和 actor_id 等等。此外,X-Lab 的数据集本身是其开源数据指标工作的数据基础,维护投入力度和问题响应速度更可靠。
在数据展示层面,我选择了 ClickHouse 去年官方支持的 Apache SuperSet 系统。你可以选择 follow 下面两个文档自建系统,或者直接使用 Preset 提供的 Free Tier 服务,其中已经预装了连接 ClickHouse 所需的组件。
配置好数据源并连接上展示系统之后,就可以开始探索社群活跃指标了。
评审人数人次
我们想要评估的活跃指标是参与 Issue 和 PR 处理与评审的状况,可以从最基本的指标开始做起:数数。
把活动范围限制在 Pulsar 主仓库当中,我们可以用如下 SQL 来取得一段时间内评审 PR 的人数:
1 | SELECT |
其中第一个 COUNT DISTINCT 结果表示的是在给定时间段内有多少个不同的 Reviewers 参与,而第二个 COUNT DISTINCT 的结果则是计算人次,即只把同一个人在同一个 PR 当中的 Review 动作合并,而不是把同一个人所有的 Review 活动都做合并。
在 SuperSet 的 UI 上做一些配置,我们可以把上面的 SQL 对应到下面的折线图:
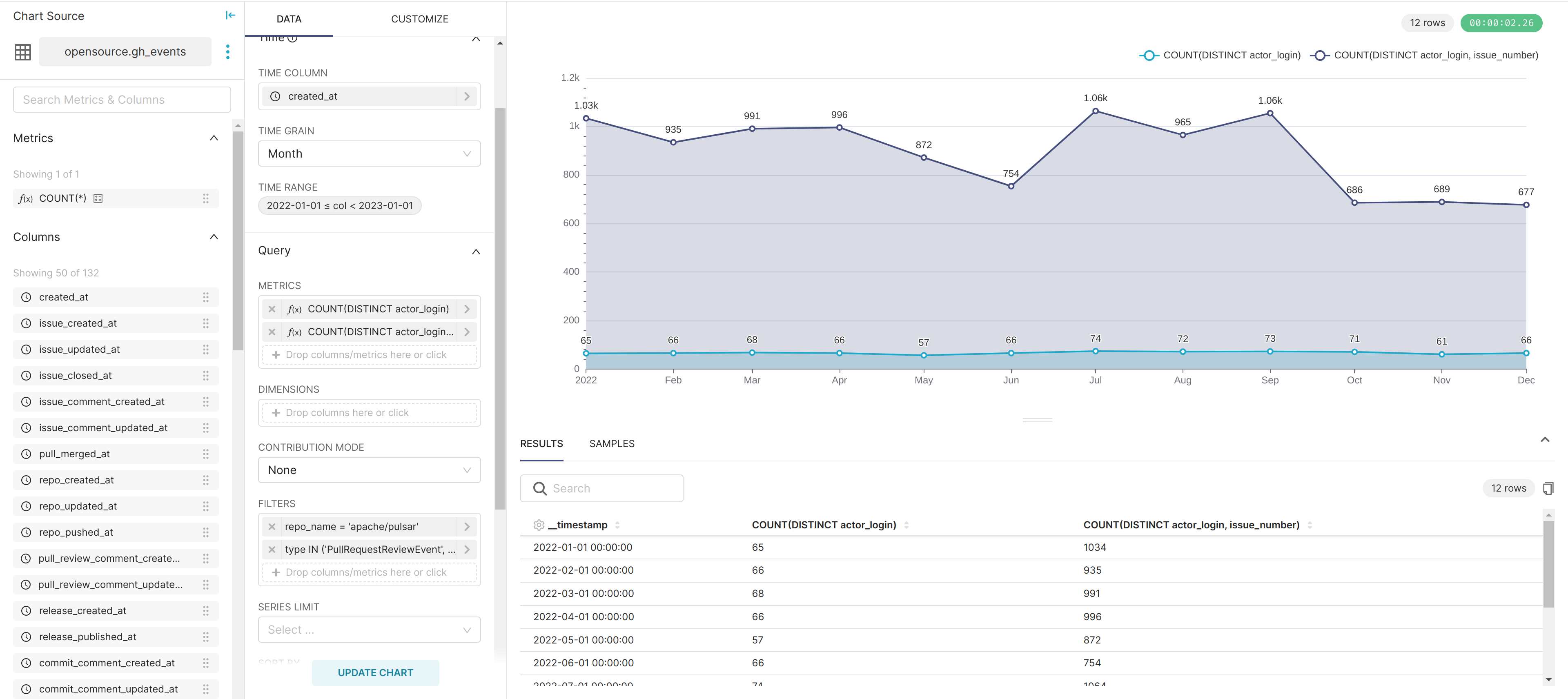
可以看到,Pulsar 社群在去年一年的 Reviewer 数量维持在 60~70 人之间,而在 10 月之后 Review 人次计数有所下降。
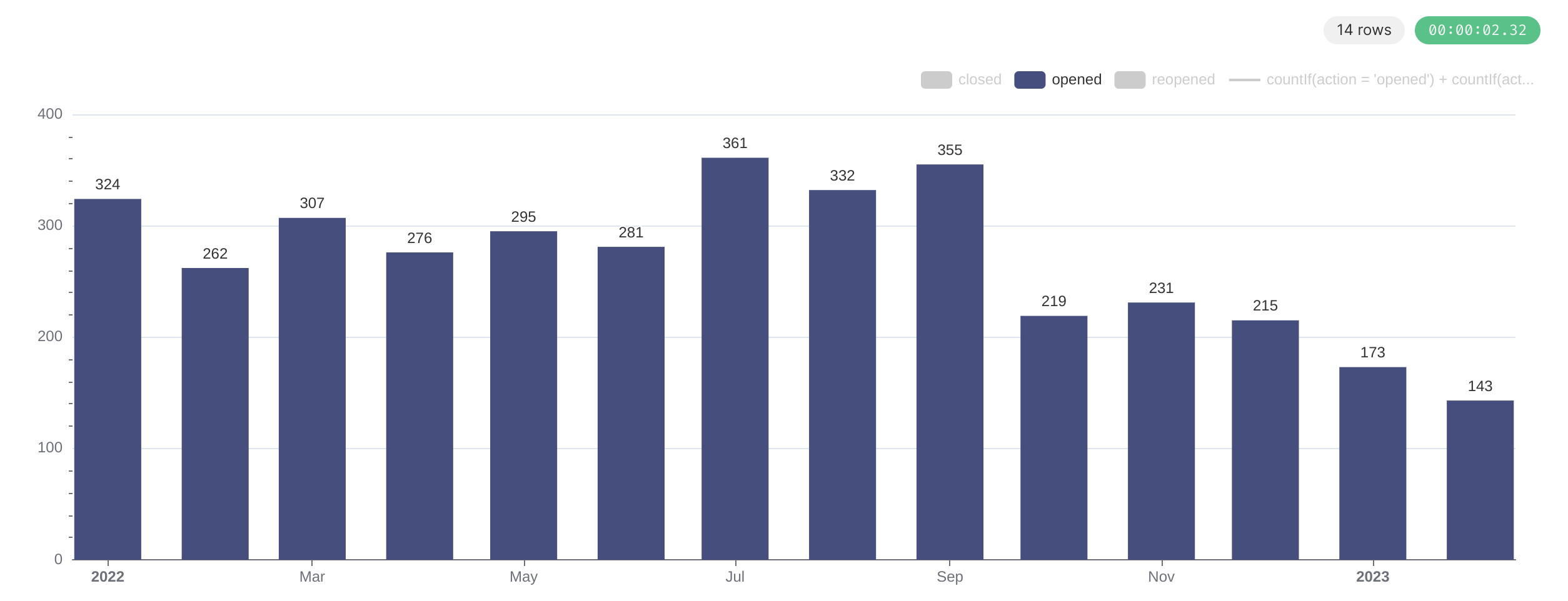
对这个数字的解释,人数上,Pulsar 社群的活跃 Reviewer 群体没有大的变化。人次上,在年中开始发布 2.11 之后,出现了一系列测试出来的回退,核心开发者专注于解决这些回退,而解决回退最好是尽量少的改动,因此 PR 的总体新增数量少了。同时,cheery-pick 和处理回退的 PR 相对直观,往往只需要一两名 reviewer 赞同就已经合并,而不会像新功能一样有大量的成员发表意见。
交叉对比 PR 创建数量的图,可以印证这个想法:
最后,我们以 DISTINCT Reviewr 的人数为指标,比较一下知名的消息系统项目的活跃情况:
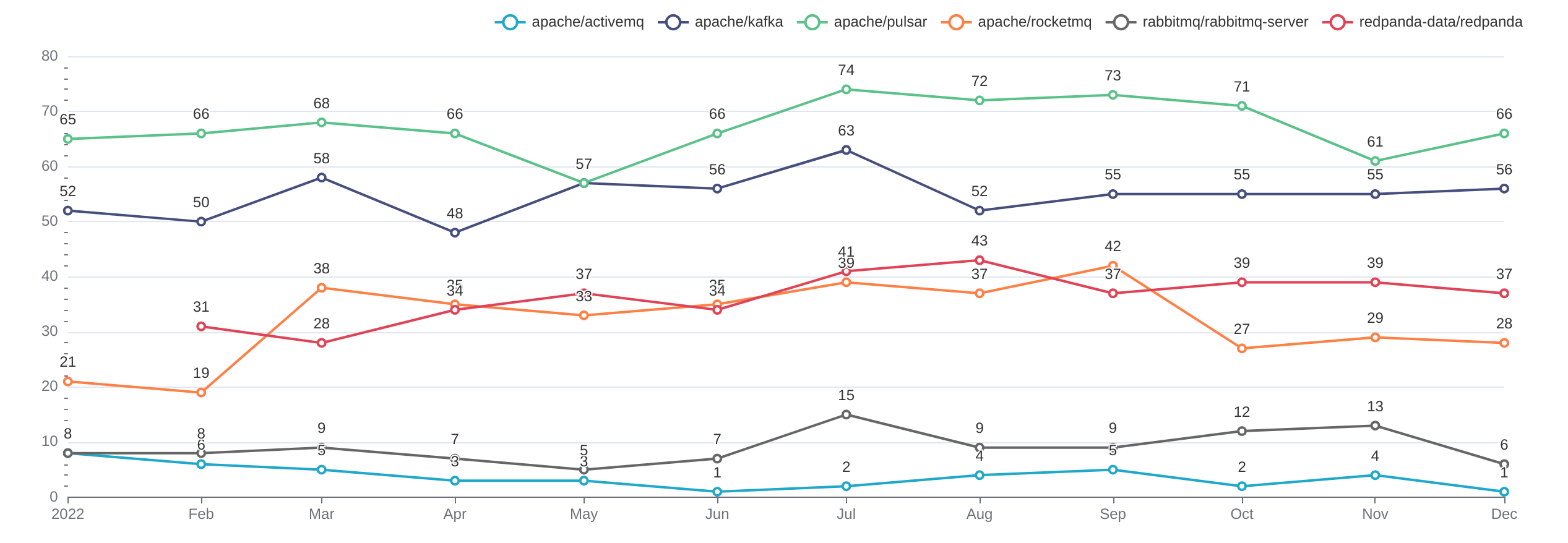
可以看到,在这一维度下,Pulsar 的活跃度是最高的,Kafka 次之;RocketMQ 和 RedPanda 是下一个梯队;而 ActiveMQ 和 RabbitMQ 的活跃度就快见底了。当然,这个数据只计算和主仓库的数值,而没有把所有仓库群加总起来算,但是加总的结果应当也是大同小异的。另一方面,核心能力的绝大部分开发工作还是发生在主仓库上,计算主仓库的活跃度可以见微知著。
平均响应时间
除了最基本的计数工作,我们还可以计算跨越一定时间的指标。例如,在工程效能乃至服务保障中都常包括的平均响应时间。结合我们这里想要评估的 Issue 和 PR 处理与评审的状况,我们可以分别计算 Issue 和 PR 从创建到首次被响应的时间,以及从创建到关闭的时间。
数据口径和挑战
不过,不同于简单计数指标,在事件粒度的数据集上做具有时间跨度的指标必定涉及数据之间的关联。如果不是类似 Apache Pulsar 活跃参与者每月看板这样,在取出数字后再经过程序处理,而是类似上面直接使用 SuperSet 作为一站式数据分析展示工具,那么关联数据的需求映射到 SQL 当中就是 JOIN 的语义,这会导致查询复杂度陡然上升一个量级,写出正确或者说合理的查询面临诸多挑战。
第一个是数据关联本身的复杂性。
要想知道具体一个 Issue 从创建到首次响应,再到被处理完毕一共花了多久,最准确的方法是通过 GitHub API 直接查询 Issue 的元数据,首先看它是否被关闭,如果被关闭,是何时被关闭。进一步地,列举 Issue 上的 comment 并取得最先提出的那个的时间,与 Issue 创建时间求差。
然而,这类数据是变化的,即使每天定时任务同步,也只能给特定的一个查询使用,从数据治理角度来说成本太高,最好是就写一个程序加上缓存硬算。这不仅脱离了 SuperSet 提供的框架,本身也会被 GitHub API 的 rate limit 限制。
从 GH Archive 数据集的事件信息出发,要想做这样的计算,就得首先取得 Issue 编号,再和其他 Issue 系列事件关联,适当排序后才能得到正确的结果。为了减少关联的复杂性,往往分析存储的每行会冗余信息。ClickHouse.com 和 X-Lab 的数据集都是一张大宽表,而 X-Lab 的数据更是每行都有 issue_created_at 和 issue_closed_at 这样的预聚合信息。
第二个是数据关联对数据质量的高要求。
SQL 查询要想得到正确的结果,能不能正确关联上多个事件是非常重要的。而实际数据集至少会面临以下问题:
- 数据丢失。GitHub 本身的服务就是不稳定的,API 上能查到服务恢复后的状态,但是事件信息说丢了就是丢了。很多基于 GH Archive 数据集计算的结果在涉及 2021 年 10 月的数据时就容易出错,正是因为 GitHub 那一个月丢了近三天的事件数据。
- 异构社群。例如,有些社群会用机器人来做首次回复,计算社群活跃度计入和不计入机器人的行为显然是不一样的。而不同的社群有不同的自动化工具和流程,进行数据关联时需要处理这些细节问题。
- 不单调的数据。计算 Issue 创建到首次响应的指标相对还是简单的,因为第一次响应是个确定的指标,一旦得出结果就不再变化。但是从创建到关闭并不是,因为还有 Reopen 的情况。如果要把 Reopen 的情况考虑进去,数据口径和计算方法就需要重新评估。
第三个是关联时间的指标的口径差异。
OSSInsight 和 OpenDigger 对上述两个时间数据的算法是以结束时间为基准的,即它们所说的 2022 年 12 月 Pulsar 社群 Issue 创建到关闭的平均时间,指的是在 2022 年 12 月被关闭的 Issue 从创建到关闭的平均时间。这样说你可能还没感觉出问题,我举个实例:我在 2022 年 11~12 月关闭了一大批年代久远的 Issue 和 PR 的行为导致 OSSInsight 上的指标在这两个月突然变差:
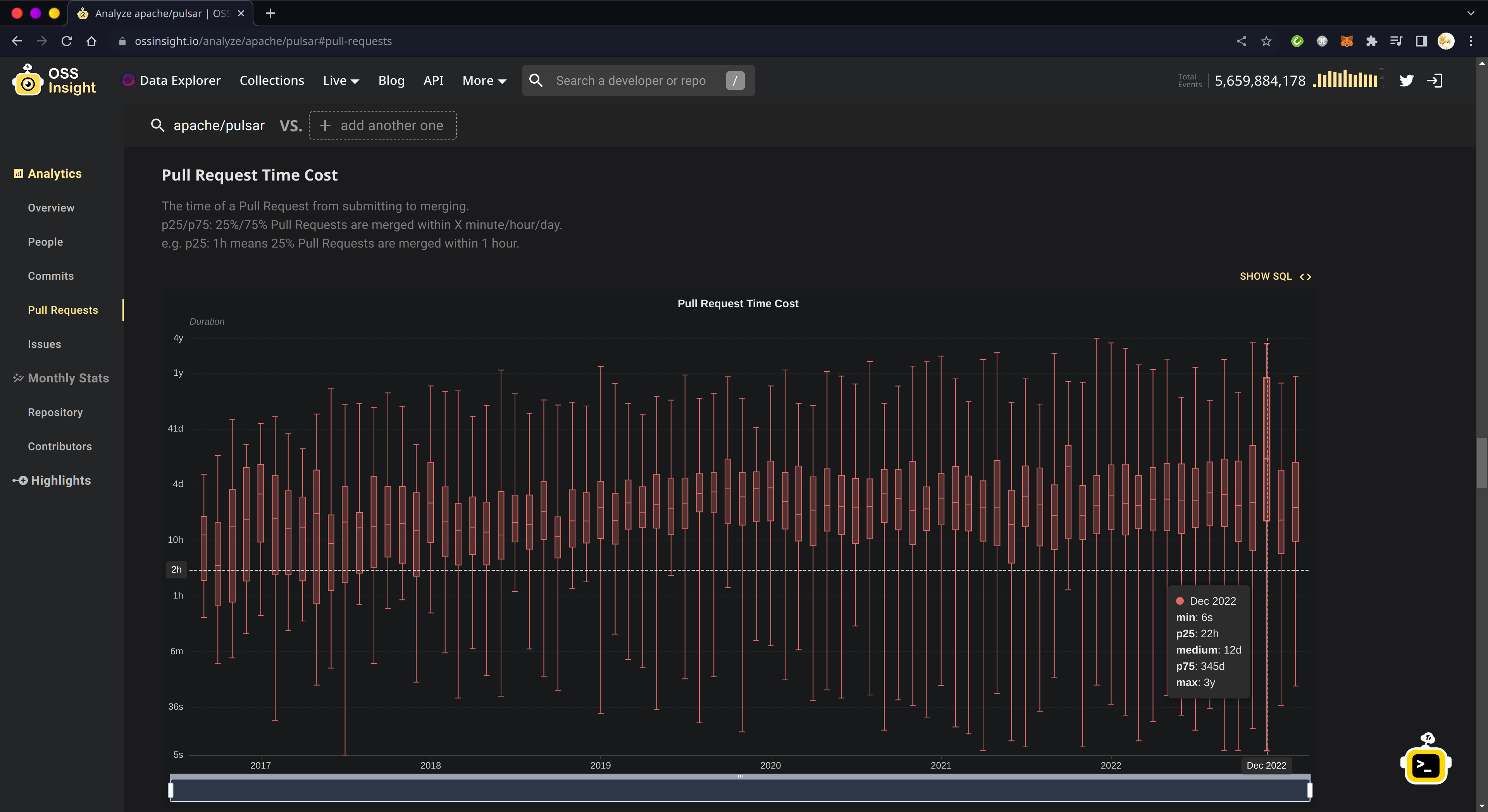
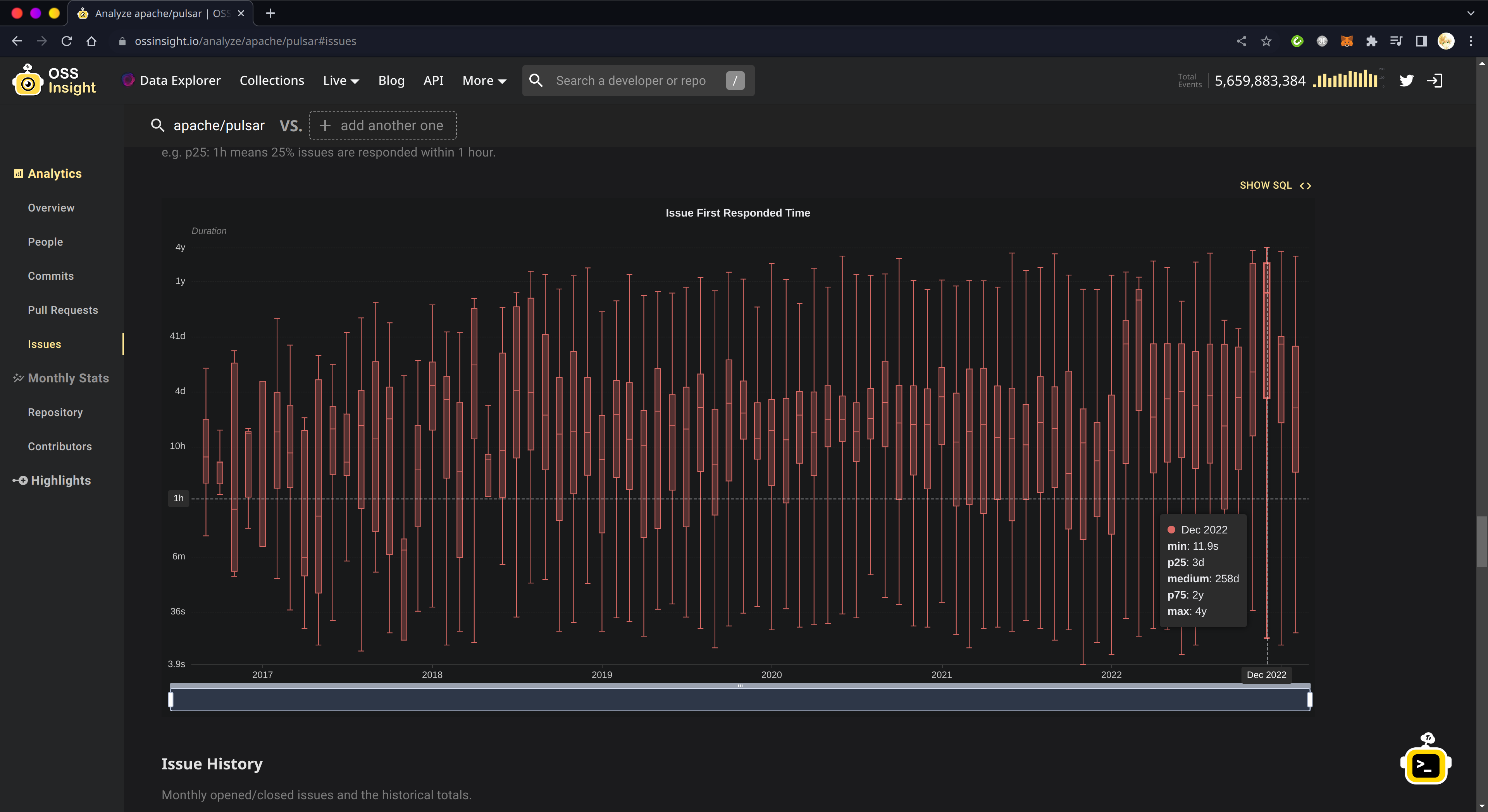
但是,实际上这与这两个月新创建的 Issue 和 PR 的处理实效关联不大。
同时,可以注意到 OSSInsight 只给出了 Issue 首次响应,以及 PR Merge 的时效。PR 关闭后可以重新打开,但是合并后则不再能转变状态。这一点,加上从结束时间倒算时间跨度,都是为了好算而做的选择。
下面,我会说明我所采用的指标口径、结果及社群之间的对比。
指标结果与对比
我所计算的时效指标,时间分区的逻辑是以开始时间作为基准的,即 2022 年 12 月 Pulsar 社群 Issue 创建到首次回应的平均时间,指的是在 2022 年 12 月期间新建的 Issue 被首次回应的平均时间。这个首次响应可能发生在 2022 年 12 月以后的任何一个时间。
不过,马上你就会发现两个问题:第一个是如果 Issue 迄今为止还没被响应,那这个时间就是未定义的;第二个是按照这种算法,计算出来的时效一定不会超过从创建到当前的时间,换言之,这个月的时效一定不会超过一个月。
为了辅助以开始时间作基准的指标逻辑,这里需要额外计算 Issue 和 PR 被处理的比例。我先展示最终计算得到的图表:
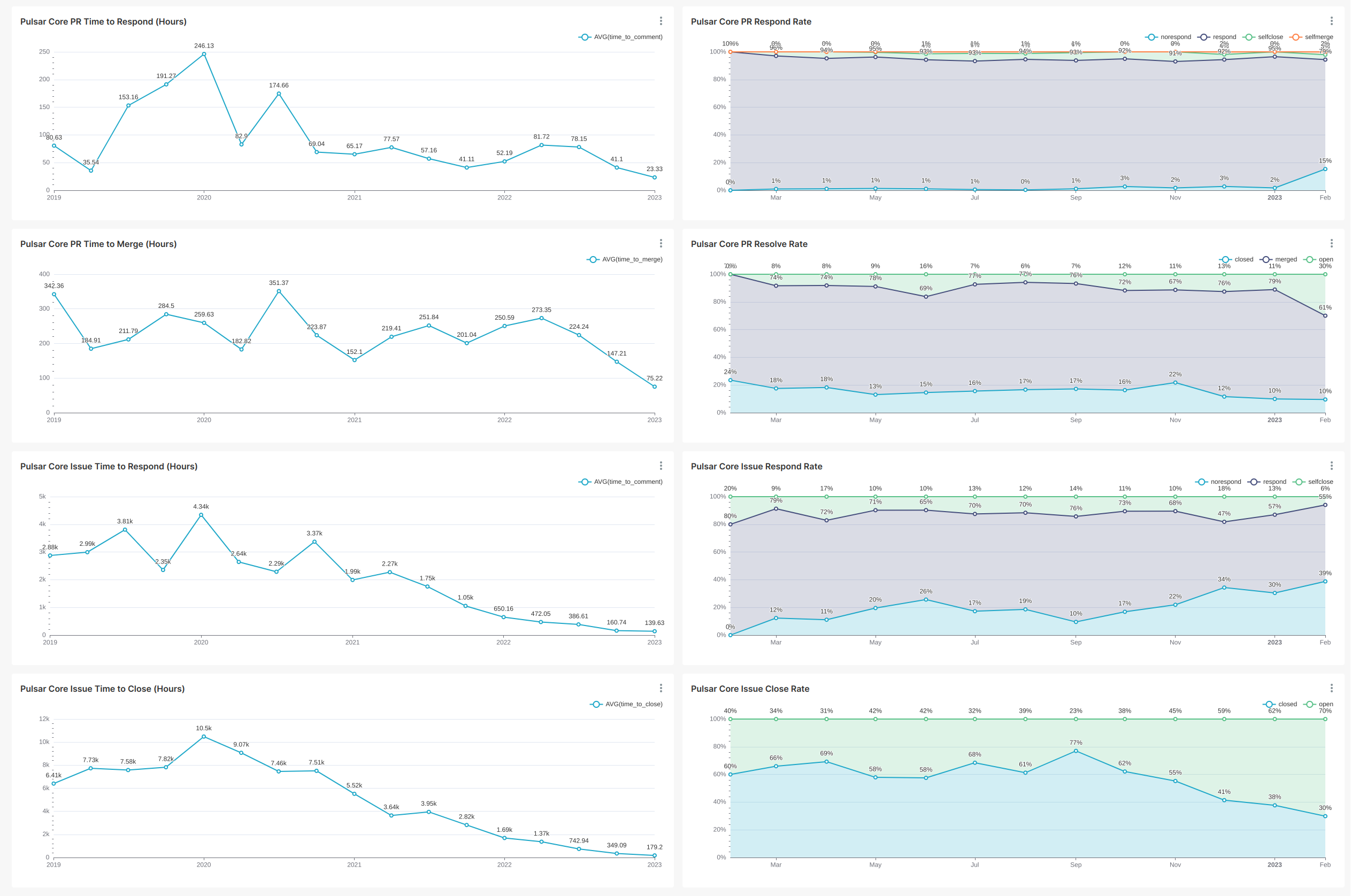
右边一列就是区分所有在给定时间段内创建的 Issue 或 PR 的响应情况占比。可以看到,如同上面说明的,Issue 和 PR 创建的时间越近,其得到处理的比例就越小。而处理时效仅考虑被处理的情况,近期的数据总是相对较好。
实际在指导社群开展工作的时候,可以使用类似:在未处理 Issue/PR 比例不超过 N% 的前提下,平均响应时间不超过 M 小时。
不过,由于后来响应会导致原先的平均值被离群值拉高,所以在执行时可以采用分位数的维度来减少离群值的影响,同时仅在每月一号当天查看上个月的情况,而不是一直监控。
具体的计算 SQL 语句,以 PR 的回复时效为例,写作:
1 | SELECT issue_number, |
由于 X-Lab 的数据做了一些预聚合,计算 PR 合并时效可以不用 JOIN 语句:
1 | SELECT issue_number, |
计算比例的 SQL 查询结构相同,但是在最外层 SELECT 仅保留 issue_number 和 opened_at 两列,并用 CASE WHEN 来区分类别:
1 | -- Respond -- |
Issue 的情况大同小异,需要注意的是也需要从 IssuesEvent + opened 的查询里获取 issue_number 的值,而不能直接用 gh_events 里的 issue_number 字段,因为后者还包括 PR 的情况。
最后是同类社群之间做一个指标的比较。由于 Kafka 的 Issue 用 JIRA 来管理,同时不同体量的社群在时效上会有较大的区别,例如线下集中开发的为主的团体几乎总是能立即响应团队内部的需要,因此这里只对 PR 的响应和合并时效,针对 Apache Pulsar 社群和 Apache Kafka 社群做一个比较。
PR 响应时效的比较结果如下:
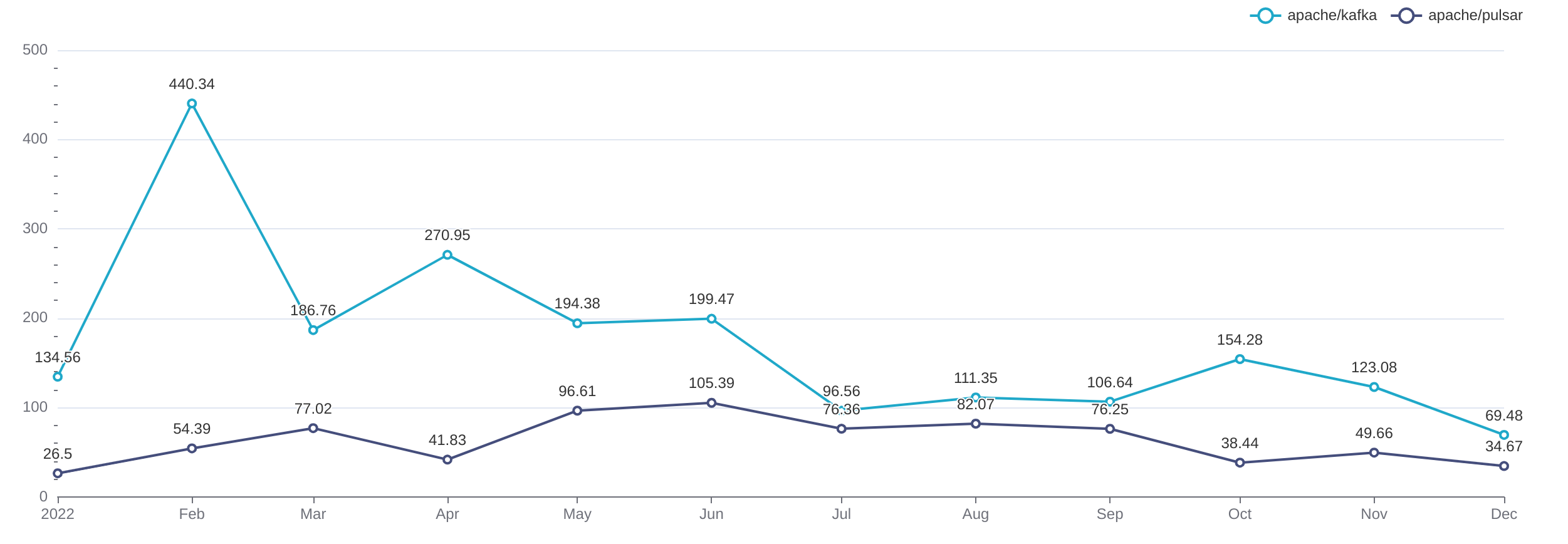
PR 合并时效的比较结果如下:
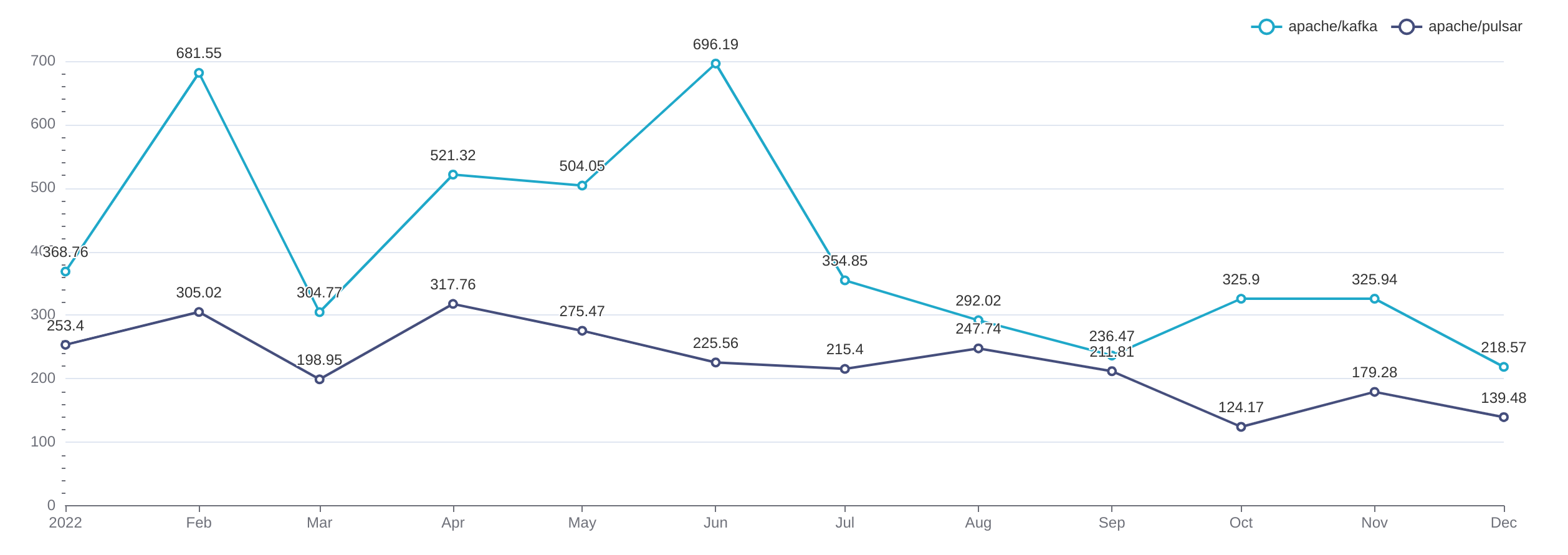
可以看到,在去年一年的时间里,Pulsar 的社群活跃度在这个维度上全面超过了 Kafka 社群。
小结
应该说,Pulsar 社群的活跃,一方面得益于其丰富的功能集带来的海量开发需求,另一方面也是社群多样化的成员组成带来的活力促进的。不同于 Kafka 上游主要依靠 Confluent 公司的雇员开发,一旦公司技术转向就会活力骤减,Pulsar 社群从提供商、集成商到应用企业,再到喜欢完整的 MQ 语义的个人开发者,不同人的需求在这里交汇和实现,与参与者同等数量的 Reviewer 参与评审,为软件长青提供了坚实的社群保障。
应该说,Pulsar 目前的开发者社群活跃度,还能够接纳不少寻找分布式消息系统的架构师,以及想要学习消息系统概念与实现的开发者。我在过去的半年里,逐步撰写了 Pulsar 社群的开发者指南,以期能够帮助到有意愿的开发者快速搭建一个本地开发环境,并参与到典型的开发活动当中来。此外,我还会在接下来的一两个月里,梳理出 Pulsar 社群生态的全貌,从而展示 Pulsar 生态的价值与其目前需要帮助的部分。按照《共同创造价值》的思路,这样就可以回答“我能为社群做什么”以及“应该怎么做到”的两个问题。