如何处理 Good First Issue
我在《GreptimeDB 社群观察报告》当中提过,GreptimeDB 的 good-first-issue 流转速度极快,大部分容易上手的工作往往在一周甚至两三天内就会有人认领,并且完成的情况也还不错。这个体验很难得。
在最近一些 Good First Issue 的流转过程中,我重新发现了一些典型的模式。正好同大家分享一下我对于如何处理 Good First Issue 这个问题的看法。
还是先看几个案例。
第一个案例算是标杆:
- Support automatic DNS lookup for kafka bootstrap servers
- feat: Support automatic DNS lookup for kafka bootstrap servers
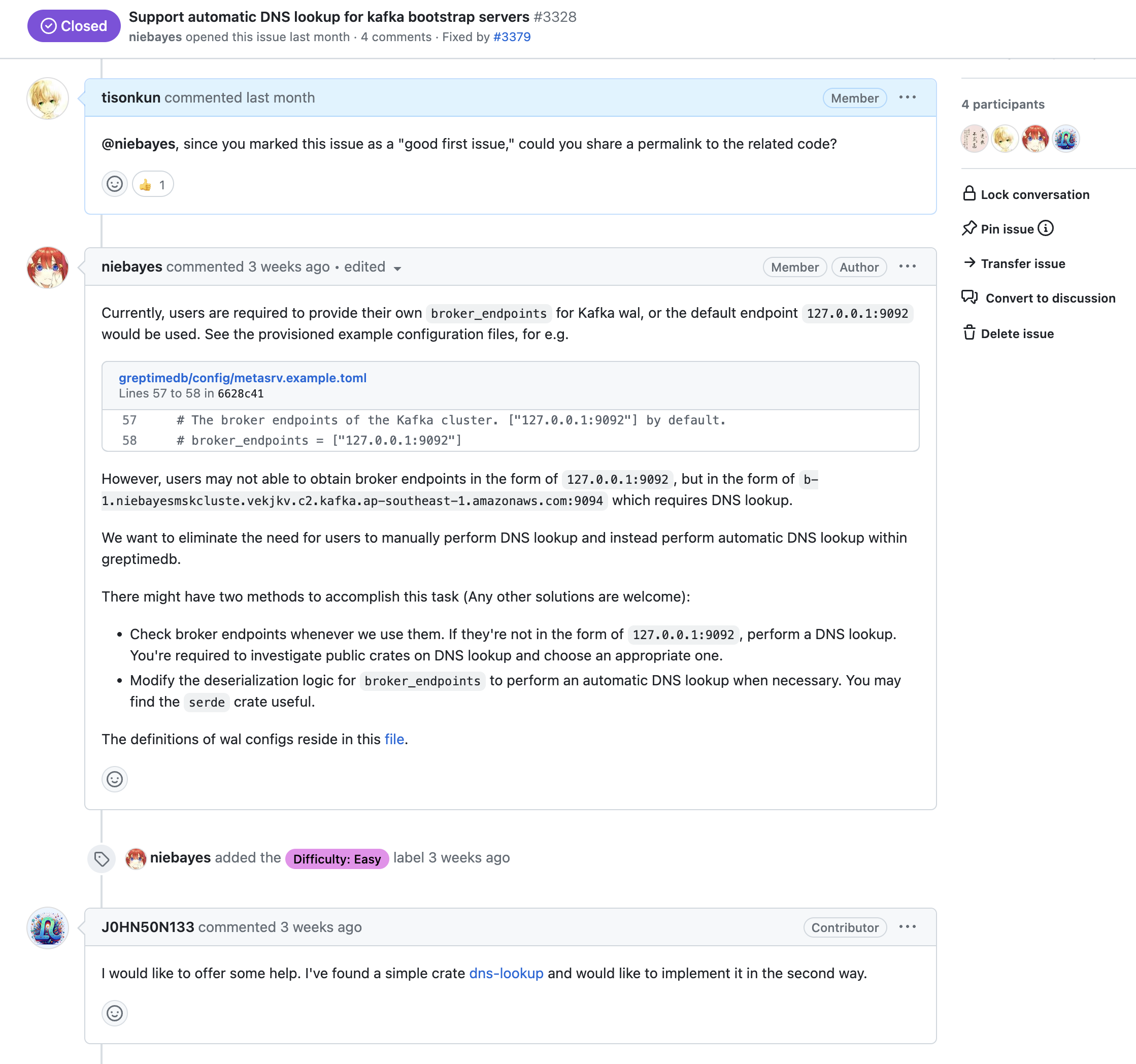
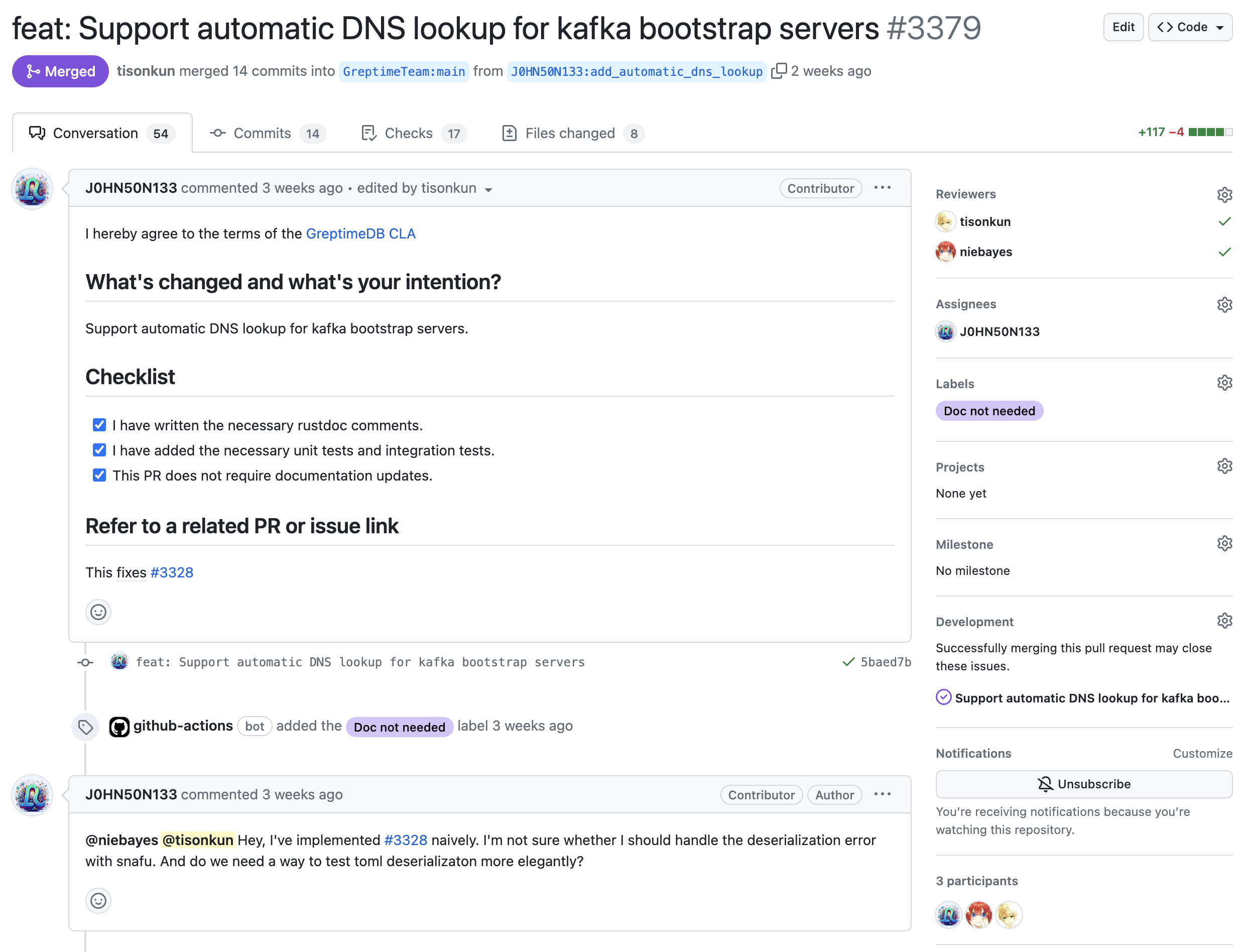
可以看到这里有两个要点。
- Issue 上仔细说明了问题是什么,为什么要解决这个问题,相关代码在哪里,可能的实现思路是什么。
- Pull Request 里作者积极的提问,并且说明他做了什么改动,有哪些 alternative 是考虑过但是不可行的。
这位 contributor 后来也开始参与到其他 issue 的解决中。
第二个案例介绍了一种处理 stale assign 的方法:
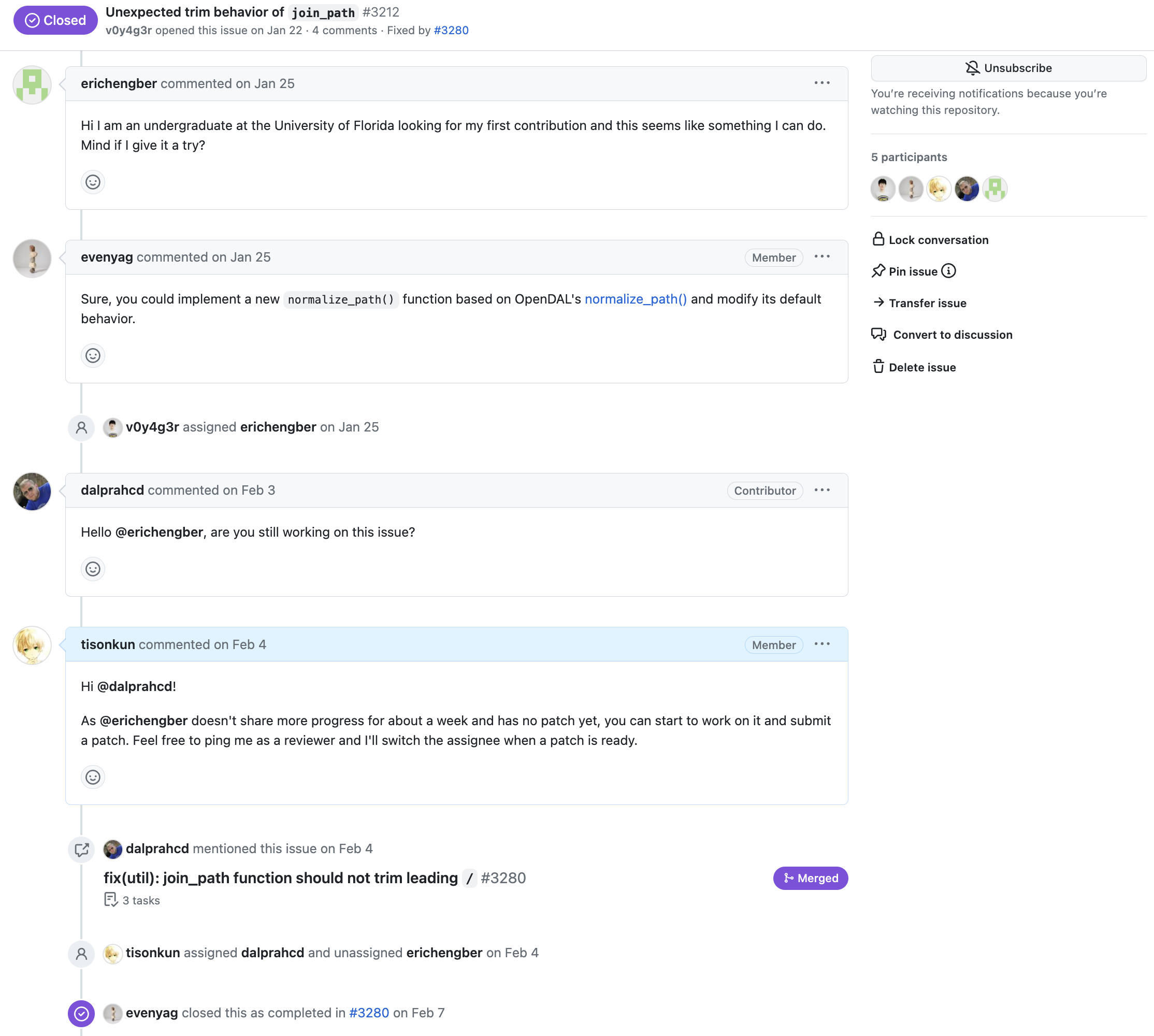
注意这里我并没有直接 assign 给这位新出现的开发者,而是在他提交 PR 之后才 assign 给他表示这个 issue 已经有人开始工作。当然,如果他能在 issue 中表达任意有效信息推动 issue 前进,我也会 assign 给他。
第三个案例是我相对担心的:
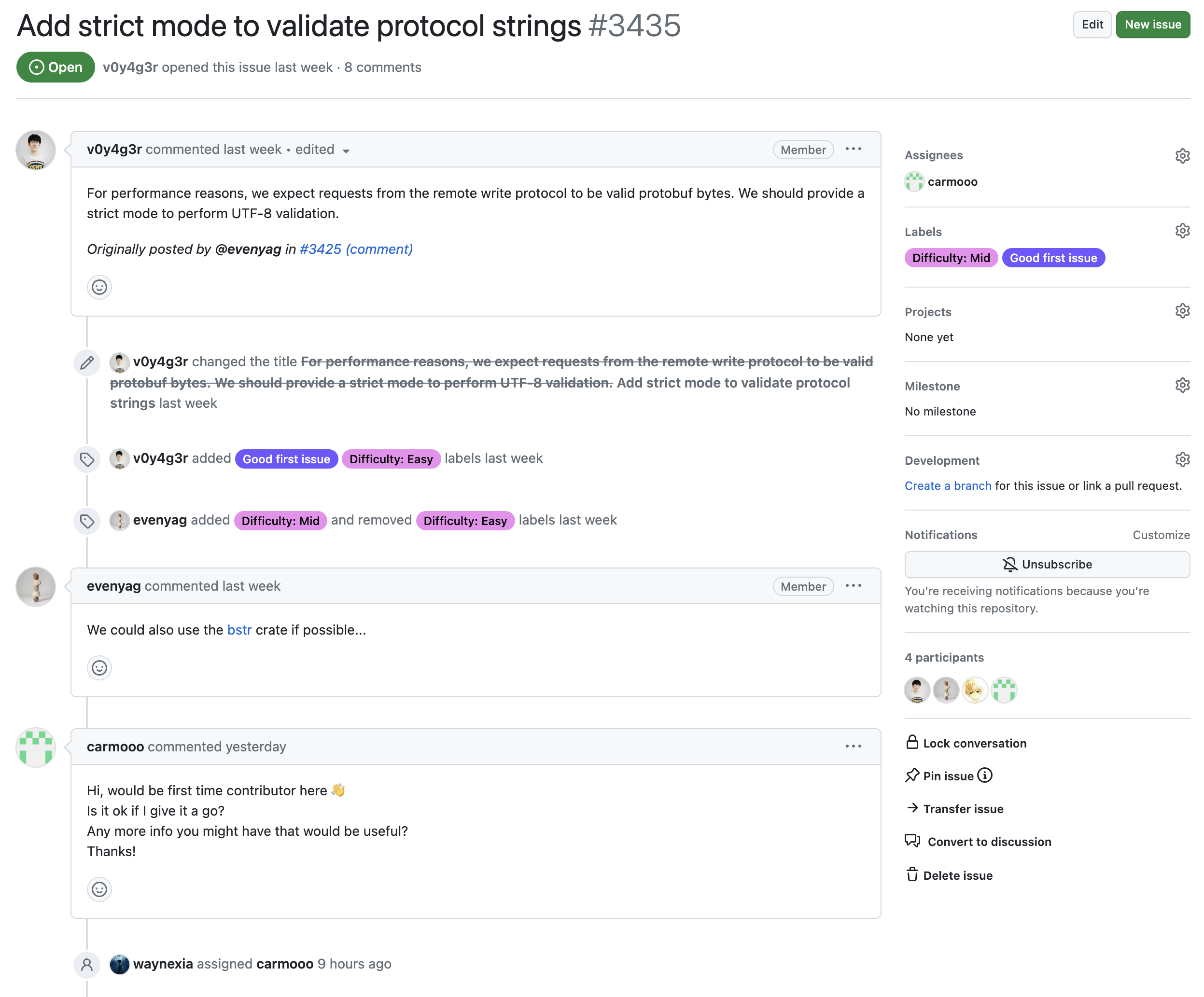
因为 issue 的描述我读完以后都觉得,可能需要耗费相当时间梳理清楚相关逻辑。这个时候一个没有过任何开源项目 contribution 经验的新人贸然说要开始接手这个工作,且不说明他的计划,也没有任何问题要追问。在我的记忆里,这种 assignee 很容易回头发现搞不定。如果能主动说自己搞不定,unassign 还好,但是更多人是默默离开,一言不发。
于是我追加问了一下他的计划:
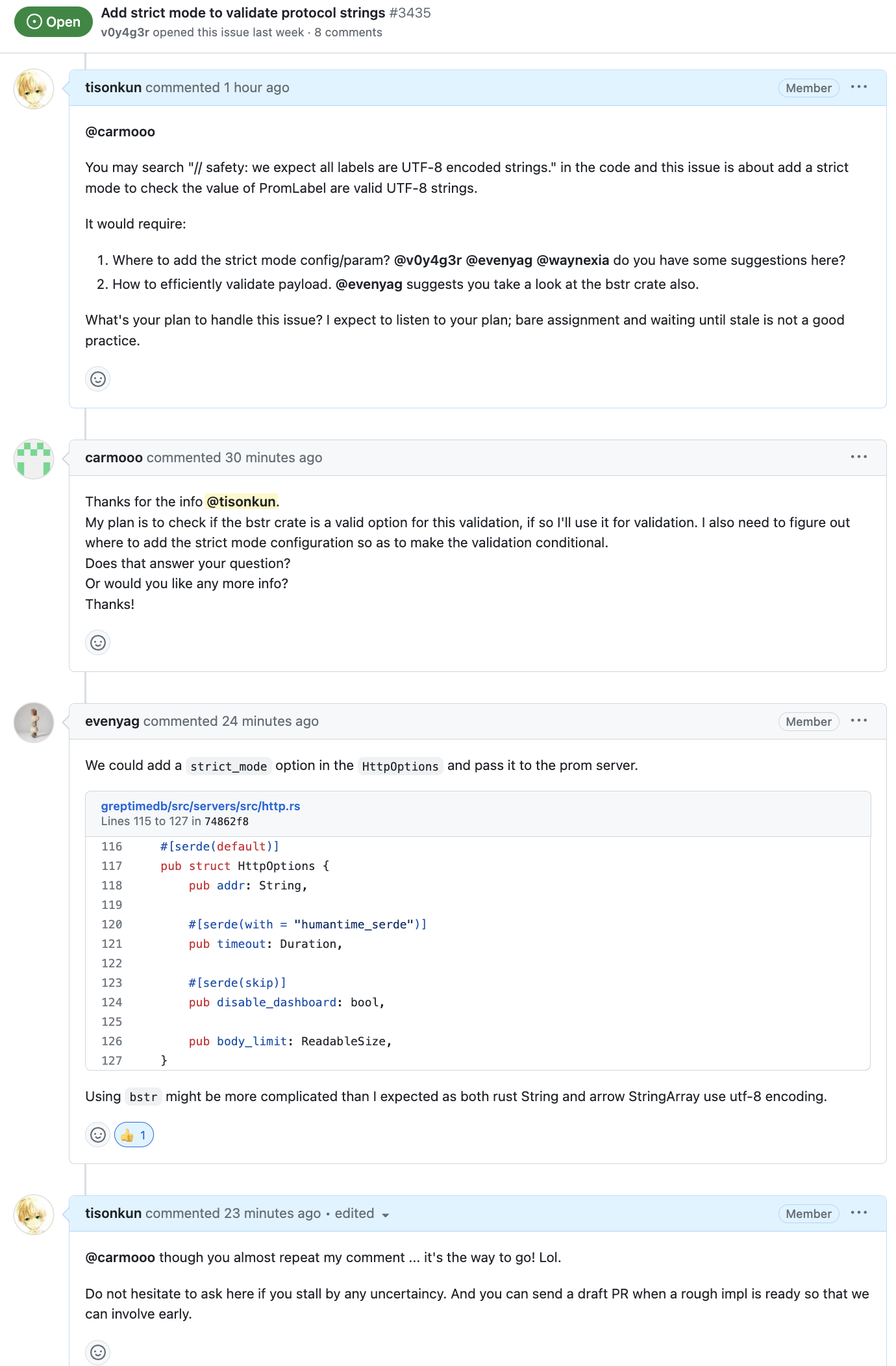
嗯……虽然有点抽象,但是至少多产生了一些有用的信息,暂且信一回。
关于这个问题,我有一段相关的论述:
Assign contributor 的时候可以做个背调,或者直接问一下 TA 的实现计划,除非 issue 确实是闭着眼睛都能做的。另一方面,这也跟 good first issue 有没有相关代码链接,有没有写清楚需求有关。比如上面的典范写清楚了,就容易让 contributor 上手做起来。
Contribution 不只是上来写代码,能经过交流把 issue 往前推进一步,对项目都是有帮助的。因此 issue 也不一定每个都要写得那么详细,毕竟大佬可以自己脑补很多内容。只是很多新手,他不知道可以问问题,或者就模糊地问一句“你有什么可以帮我的吗”。
不用害怕劝退潜在的参与者,如果正常交流都不能回答,大概率不能解决问题,或者做出 PR 来很抽象,review 起来想死。当然,我也见过不用太多交流也能做得很好的,那种大佬会一个 PR 拍你脸上,也不会被劝退。
最近比较像的比如这位:
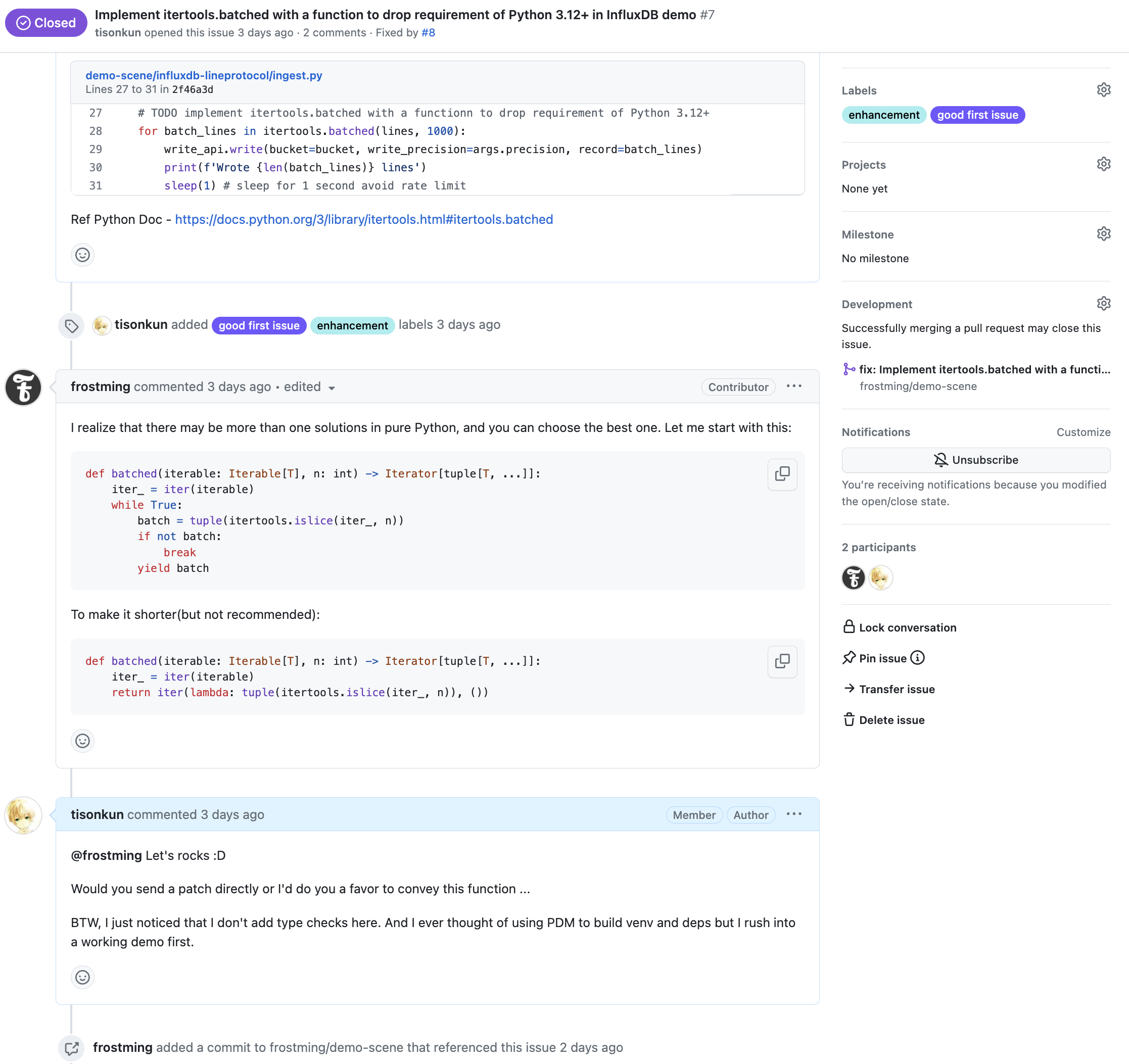
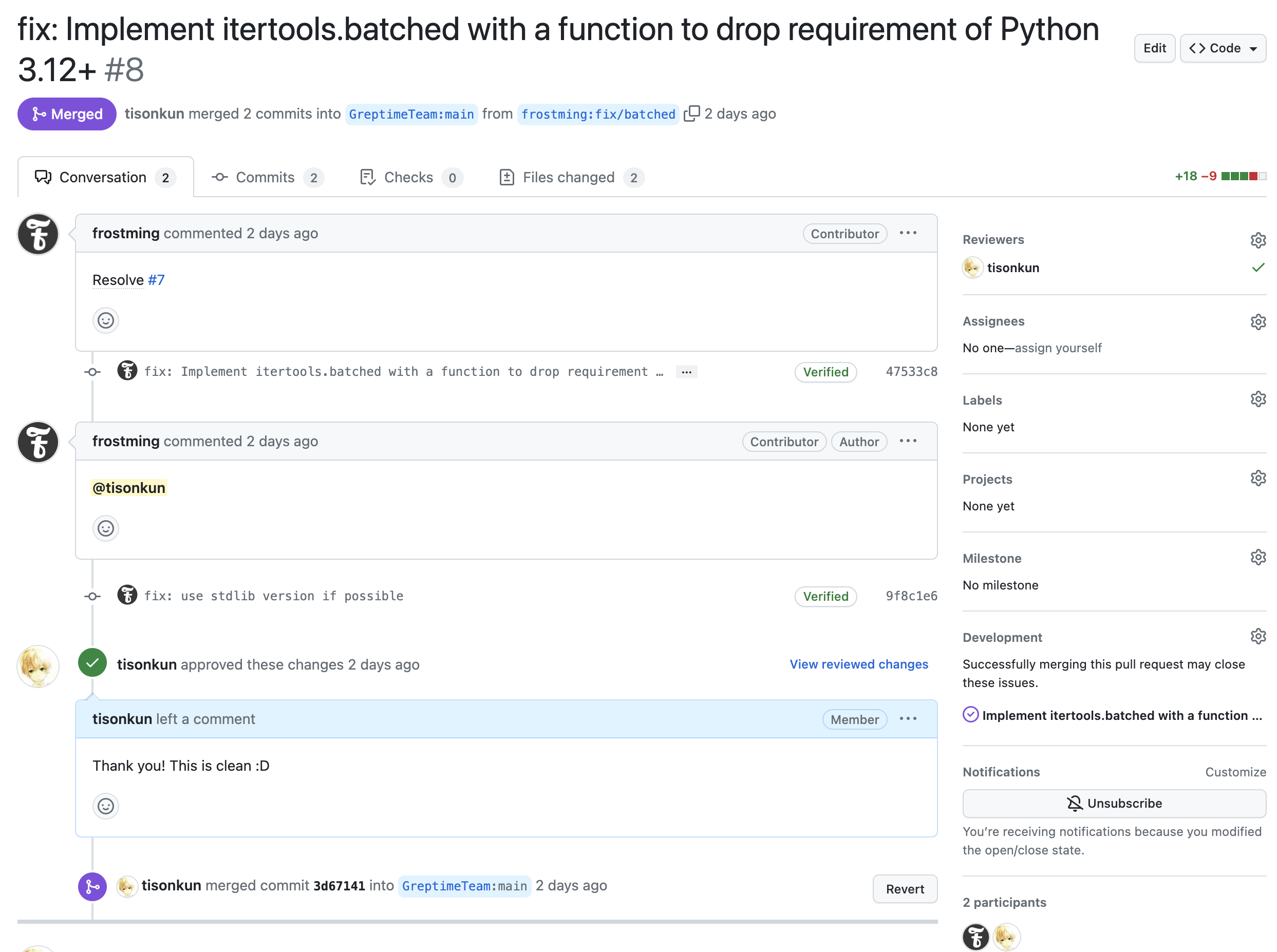
不过无论如何都有可能出现 assignee 出于各种原因无法完成 issue 的情况。从维护者的角度说,兜底可以问一下进度然后 unassign 掉。这个是可以自动化的。我在 GreptimeDB 上记了一个 Good First Issue 来实现这个自动化:
其他相关的话题这里就不展开了,如果各位有兴趣听,可以回复我来讲。
- 不同文化背景的 Assignee 的倾向;比如这位是比较典型的。
- Good First Issue 怎么设置比较合适?
- 企业开源项目如何在 Issue 上与跨越组织边界合作?
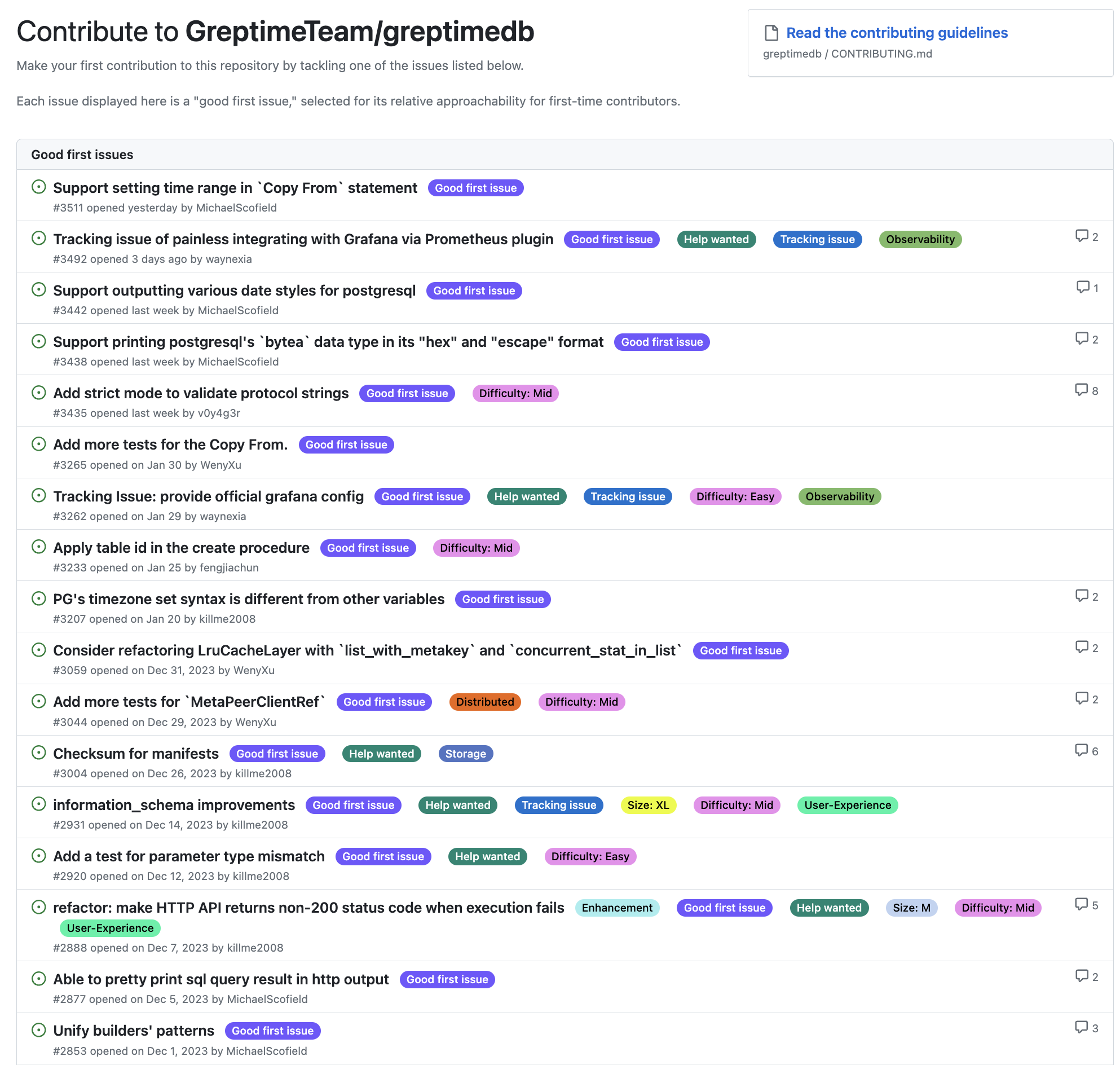
对于关注 GreptimeDB 想找机会参与的读者,现在主仓库还有一些未解决的 Good First Issue 可以上手,即使有人 Assign 了,如果过去数周没有什么进展,也可以由你来接手推进。
如果你不是 Rust 开发者,GreptimeDB 也有各个语言的客户端正在开发。对于 DevOps 开发者,GreptimeDB 的命令行工具 gtctl 正在准备发布第一个版本,我和项目作者都会及时处理上面的信息。对于前端开发者,GreptimeDB 的 Web UI 也是一个独立的开源项目。
总的来说,GreptimeDB 是一个值得参与的开源项目。其软件产品目标是成为一个高效、实惠,且可以处理分析大规模时序数据的云数据库。目前已经可以替换 InfluxDB 和作为 Prometheus API 的存储后端。